

Data is the new oil of the modern digital economy. Across the globe, enterprises are generating data at a pace like never before. This data is in different formats and from various sources — millions of financial transactions, sensor data from IoT devices, industrial processes and automobiles, and from our ubiquitous smartphones, fueled by our addiction to social media. So let’s have a look at why Big Data is so important and why Hadoop is a life saver when it comes to the analysis of this data.
There is a tremendous amount of data that is getting generated. Activities like social media interactions, surfing the Internet, user communications, online shopping, sharing and Internet searches produce massive streams of data. These data sets are so large or complex that traditional data processing application software are inadequate to deal with them. To quantify the data that is getting generated and to put things in perspective, let’s do a quick run-down of the vital statistics of the modern digital world:
- There were 5 exabytes of information created between the dawn of civilisation through 2003, but that much information is now created every two days.
- By 2020, one million devices are expected to come online every hour.
- The Weather Channel receives more than 18 million weather forecast requests every minute.
- Data is expected to grow to 44ZB by 2020.
- By 2020, the average age of an S&P 500 enterprise is expected to be about 12 years. This was 60 years in 1960.
- More than 90 per cent of the current world data was generated in the last two years.
- IoT devices are expected to grow to 200 billion by 2020.
- Over 4 million videos are viewed on YouTube every minute.
- On an average, Google processes over 40K searches every second. This translates to a whopping 3.5B searches very day.
- Over 65 billion messages are sent via the WhatsApp mobile app and Web client every day.
- More than 300 million pictures are uploaded to Facebook every day.
- Netflix users stream around 70K hours of video every minute.
- Social media is the biggest generator of data. Every minute, around 500K tweets are sent, over 150K Skype calls are made, over 100 million spam emails are sent, and around 600K pictures are shared on Snapchat.
The data that is getting generated has certain specific characteristics which qualifies them as Big Data. These characteristics are called the 5 V’s of Big Data
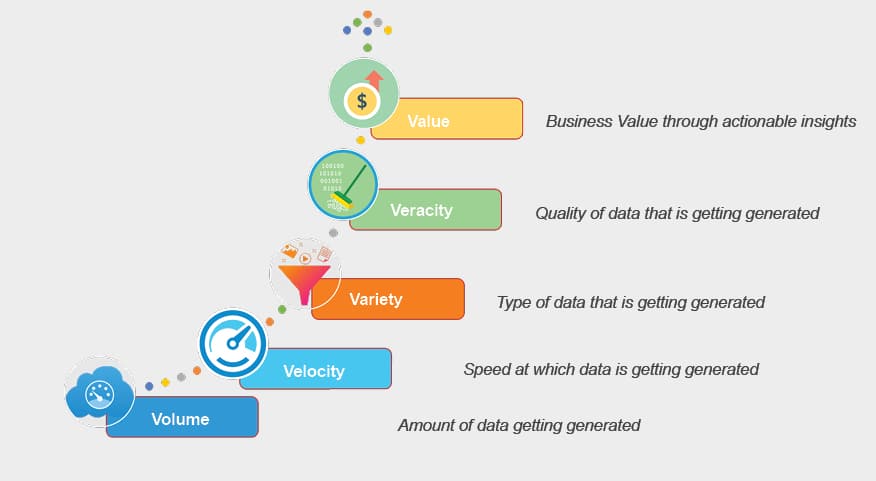
The Five Vs of Big Data
All that gets classified as Big Data shares certain specific characteristics that are called the Five Vs, which include the following.
Volume: This refers to the humongous amount of data that is getting generated every day, every minute and every second. Data that is far more voluminous than traditional relational database systems can manage constitutes Big Data. These huge data sets warrant the use of a different computing paradigm to store and manage them. Big Data leverages the power of distributed computing to extract actionable insights out of huge data sets.
Velocity: This refers to the speed at which data is getting generated. The need to capture and act on the data generated by millions of sensors, mobile devices, social media or financial transactions in real-time or near real-time has become unavoidable. Big Data technology can be leveraged to extract insights from the data streams itself, instead of having to save it in some database.
Variety: This refers to the different types of data that we can leverage to extract insights. Most of the data analysis in the pre-Big Data era was confined to structured data based on relational database tables. With Big Data technology, we can perform analysis on unstructured data, semi-structured data, quasi-structured data as well as structured data. Around 90 per cent of the current world data is unstructured and comes in formats as diverse as images, audio clips and videos, sensor data, social media data, logs, clickstream data and so on.
Veracity: This refers to the quality of data. To what extent is the data reliable and dependable? With different varieties of Big Data, it is impractical to control the data quality or expect that it is always reliable and trustworthy. While verifying the veracity of the data, we begin to understand the perils related with using the data for analysis and making business decisions based on it. The veracity of data also refers to how meaningful it would be to leverage the context in which the data was generated, for analysis.
Value: This refers to the ability to extract business value out of the tsunami of data. It is imperative for enterprises to clearly understand the value generated by Big Data and the measurable outcomes that it would result in. Significant value can be found in Big Data including a 360o view of the customer, personalised targeting, operational efficiency, accelerated innovation and so on.
These characteristics of Big Data and the challenges associated with managing it warrant the use of new technical architectures and analytics to extract insights and enable new sources of revenue. This new technical architecture is named Hadoop and it can be considered a life saver.
Hadoop: A panacea for Big Data challenges
For most enterprises, data related initiatives are ranked at the top of the list when it comes to investments. One of the main reasons for this is that enterprises seek to unlock value from the huge amounts of structured, quasi-structured, semi-structured and unstructured data they have at their disposal to dramatically improve business outcomes. Hadoop is an innovative, interesting and powerful framework that can even dwarf Big Data. Hadoop can be of immense help in many ways.
- Capturing and storing all enterprise data: A majority of enterprises estimate that they leverage less than one-fifth of the data they have for analysis, leaving most of their data unused. This is primarily because of the lack of analytics capabilities and ever-increasing data silos. Without analysis capabilities, it is very difficult to judge which data is going to be valuable and which is not. Data that may seem immaterial now might be a future gold mine. The cost and effort involved in managing data often results in enterprises having to make choices on what data to keep for analysis and what gets discarded. Thanks to Hadoop, enterprises now have an option to manage and analyse as much data as they want in a much more cost-effective way.
- Rapid processing: In traditional systems, data is shipped to the processing unit. This process is IO intensive and involves network hops as well. Hadoop uses a drastically different paradigm by leveraging data locality and distributed computing. In Hadoop, the processing is shipped to the data, thereby reducing the IO and network latency. In addition, processing is split into smaller tasks and multiple nodes work in parallel to complete these tasks very fast.
- Democratising analytics: Traditionally, analytics has been considered niche and has been restricted to a few strategic power users while tactical and operational users were deprived of it. The Hadoop ecosystem helps to democratise analytics by making it available to all users who make critical decisions at any level within an enterprise. In addition to distributed storage, Hadoop also provides distributed computing, which enables rapid crunching of large data volumes in parallel and at a swift pace.
- Enabling an enterprise data lake or data layer: A data lake is a central repository to store and capture all data, irrespective of its format and source. A data lake can be leveraged as a single and integrated data repository to enable businesses to ask questions which were never thought of in the past. Data from various departmental silos can be integrated in the data lake to reduce the innovation cycle, time-to-market and hence enhance the customer experience and service.
- Being cost-effective: Storing and processing Big Data on traditional enterprise hardware could be very expensive. Hadoop was created to be run on commodity hardware. There is no role for any proprietary hardware or software. Various studies suggest that the cost of storing a terabyte of data per year could be 2x to 3x less on Hadoop based systems as compared to non-Hadoop systems. With falling hardware costs, the cost savings could get even better.
With Hadoop, enterprises follow a methodology to implement their Big Data initiatives, which can be summarised as a Big Data implementation framework.
Big Data implementation framework
This comprises certain guidelines for Big Data initiatives, with various components and processes that are listed below.
Data sources: These could be diverse and spread across the organisation or outside it. Data could originate from various sources like online transaction processing (OLTP) systems, operational data sources (ODS), enterprise data warehouses (EDW), application logs, files, data streams, clickstream data, IoT data, REST APIs, machine data, cloud data or social media data. All this data could be either structured, quasi-structured, semi-structured or completely unstructured. The data can arrive either in batch mode, real-time mode or near-real-time mode.
Acquire: Enterprises can leverage a wide variety of options for acquiring data from different sources. Data from the sources is first loaded to a raw data zone, which stores the data sets in their original form without any modification. Some of the technologies that can be used for data acquisition include:
- Apache Sqoop: A service to export and import data from relational databases to Hadoop
- Apache Flume: A service which can be used to stream logs to Hadoop
- Apache Kafka: A publish-subscribe messaging system used to capture message streams
- ETL tools: Some of the commercial ETL tools that enterprises have already invested in and that have good integration capabilities with Hadoop can be leveraged
Process: Data processing includes transforming data from its raw format. After basic data sanitisation and data quality checks are performed, data can be loaded in a staging zone. After the basic checks are done, sensitive and vulnerable data can be redacted so that it can be accessed without revealing any of the PCI (payment card industry), PHI (personal health information) or PII (personally identifiable information) details. Some of the tools and technologies that can be leveraged include:
- Apache Hive: A service that provides relational abstraction on Hadoop data to query huge data sets using Hive-QL (a SQL-like language)
- Apache Spark: An in-memory processing framework specially developed for handling large scale data and analytics
- Apache Storm: A complex event-processing engine developed for processing streaming data in real-time
- Apache Drill: A framework developed for supporting data-intensive distributed applications for interactive analysis of huge data sets
- MapReduce: A Hadoop v1 programming model used to process large data sets in parallel by leveraging distributed computing
Curate: Once the data sets are organised, they are analysed in order to extract value and insights from them. Complex business rules can be applied to the data sets to convert them into a form that is more business friendly. This phase could also include applying machine learning models on the data sets for predictive use cases. For scenarios dealing with artificial intelligence, cognitive APIs can be leveraged to extract additional insights from the data. In addition to the tools and technologies used during the process phase, a few additional technologies that can be leveraged include:
- Machine learning models, which have been trained over a period to predict outcomes for the incoming test data
- Cognitive APIs: These are sets of pre-built home-grown or third party APIs catering to a specific need and business use case
Publish: After the data is processed and analysed, it is pushed to the publish layer, which comprises various components including the following.
- Enterprise data warehouse (EDW): All the extracted insights and analytics can be pushed to the EDW to cater to reporting and dashboarding needs
- Search engine: Data can be pushed to search engines like Elastic Search or Solr to address keyword based search use cases
- Message queue: Data can be made available to downstream applications by publishing the extracted insights to message queues
- REST APIs: RESTful APIs use HTTP requests to manage data
In addition to the implementation framework, enterprises also put in place a comprehensive data architecture framework for Big Data called the Lambda Architecture.
Lambda Architecture
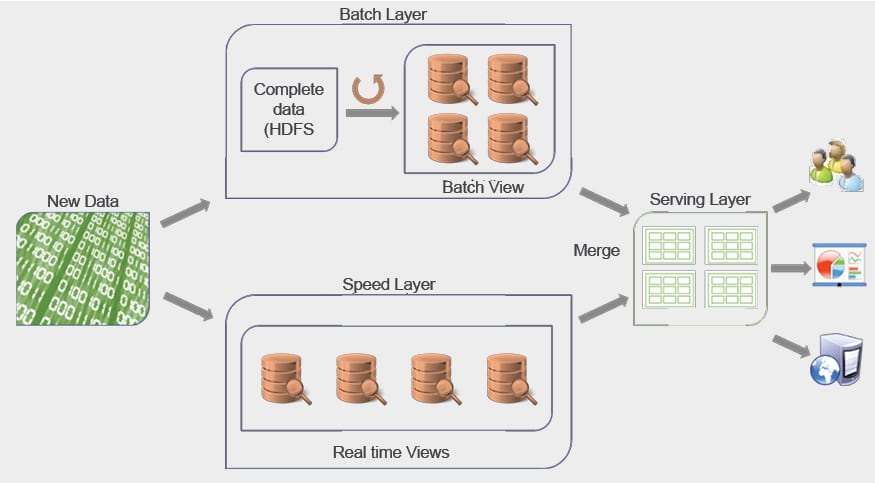
It could be challenging to design and build a Big Data solution that is fault-tolerant, scalable and caters to diverse use cases and workloads with different latency requirements. The Lambda Architecture is a generic framework that could be leveraged to design robust and reliable Big Data applications. It proposes a three-layered architecture consisting of the batch layer, speed layer and serving layer.
- All new data entering the system is sent to both the batch layer and speed layer.
- Batch layer: This caters to two primary needs. One is to maintain a master data set and the other is to pre-compute batch views.
- Speed layer: This deals with only recent data and caters to all low latency requirements.
- Serving layer: This merges data from both the batch and speed layers, and caters to downstream data needs.
- To complement the implementation and data architecture frameworks, enterprises must also take care of certain considerations when working with Big Data.
Key considerations with Big Data
To leverage Hadoop based systems as a core data layer, it is imperative that enterprises have proper governance and controls in place. Certain important aspects that need to be considered when dealing with Big Data include the following.
- Data ingestion: This helps to simplify the on-boarding of new data assets and boosts the ability to develop new use cases. A managed process should be in place to decide what data gets ingested from where, at what time and where it gets stored within the data layer.
- Metadata management: This is the ability to make a data catalogue (containing all the metadata captured during the data acquisition and validation) available to all the stakeholders.
- Security: This is the ability to authorise users and control access to data assets.
- Compliance: This monitors PCI, PII, PMI and statutory compliance of how data assets are used.
- Technology changes: Hadoop based ecosystems, which are primarily used with Big Data, are robust, complex and constantly evolving. In addition to new components being constantly added to the Hadoop ecosystem, each component by itself is being enhanced. To keep up with the latest and best developments in the Hadoop open source world and embrace them could be a challenging task.
- Data archival policy: It is very important to have a comprehensive data archival and purging policy in place. Data should be segregated into hot, warm and cold tiers and should be organised accordingly.
- Audit and logging: These functions maintain the details of the all-important activities taking place in the Big Data ecosystem.
The current buzz words in the tech world include the cloud, artificial intelligence and machine learning. In the context of Big Data, these technologies are not only very relevant but also make up an extremely desirable combination.
The cloud – a catalyst for Big Data initiatives
One of the main reasons enterprises experience delays in Hadoop initiatives taking off is the effort and skills needed to procure and set up Hadoop clusters on-premise or in their data centres. In addition, making huge investments for new business initiatives may not always be a viable option. Here is where enterprises can look to the cloud as a testbed for their new ideas. Cloud providers like Microsoft offer managed Hadoop services like HDInsight and Azure Databricks, which can be leveraged to jumpstart Big Data initiatives.
Some of the reasons why Hadoop on the cloud is a win-win situation are listed below.
- Increased agility: Setting up Hadoop on-premise can take up to a few days and would require skilled Hadoop resources. This set-up time is drastically reduced to just a few minutes on the cloud without the need of any expert Hadoop resource. All it takes is a few clicks from a browser and a few minutes to set up a Hadoop cluster on the cloud.
- Optimised costs: Enterprises can start with a small cluster that has a few nodes and add more nodes as per their needs. They also have an option to shut down the cluster during non-business hours to further optimise expenditure
- Reduced cycle time: Many enterprises are leveraging the virtually infinite storage offered by the cloud to store a lot of their data assets. The time taken to run data processing and analytics jobs has dramatically reduced due to data proximity.
- Elasticity: Enterprises often discover that the scope and the domain of their problem shift very quickly. By the time they try to address the original issue, this may either vanish or get magnified. Optimally planning the on-premise infrastructure for such dynamic business problems could be very challenging. The elasticity offered by the cloud to scale from a few clusters to a few hundred clusters can help enterprises to be more agile and productive.
- Better management: Hadoop on the cloud helps enterprises to better leverage the constant innovations happening in the Hadoop ecosystem. The cloud provider is responsible to do the heavy lifting of upgrading Hadoop components while enterprises can focus on innovation.
Big Data and artificial intelligence – A match made in heaven
The world is witnessing digital disruption and transformation at an unprecedented pace, and data is at the centre of these changes. It is difficult to think of any industry that will not be transformed by AI in the years to come.
In very simple terms, AI can be thought of as a set of technologies that empower connected machines to execute tasks in a smarter way by learning, evolving and improving upon their learnings in an iterative and recursive manner. AI has been around for decades but its growth was confined due to various reasons. Today we have access to data on demand and in real-time. We have tools and technologies to perform rapid analysis. Big Data has helped to democratise AI to a larger extent. The reason Big Data has made AI popular is simply because the former can deal with massive and complex data sets in ways that traditional data processing methods (and humans) cannot.
Big Data and AI have truly formed a great synergy, and they complement each other, bringing out the best of what either can offer individually. We need to apply AI to unlock value from Big Data and we need to feed more data to AI for it to get better and better. In short, AI is a way to navigate and unlock insights in the world of Big Data, while the latter is the way to make the former more accurate.
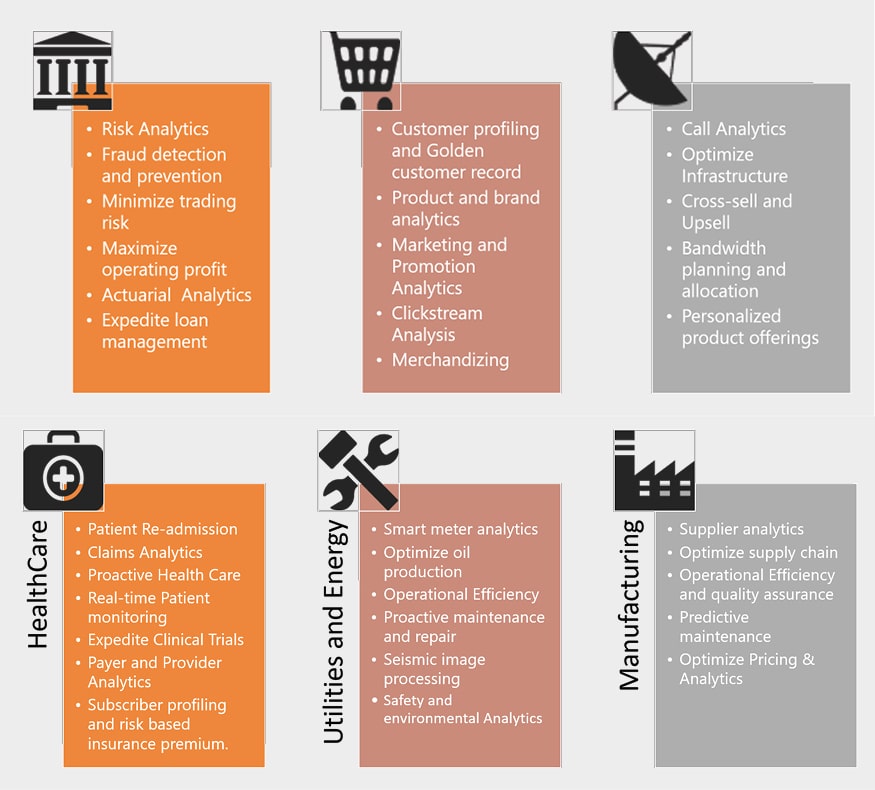
Before we conclude, let’s look at how Big Data applications are being applied across various industry verticals.
There is hardly any sector in the digital economy that is not touched by Big Data. Across all verticals, Big Data is fuelling innovation and productivity, proving to be vital for gaining competitive advantage (Figure 3).
Since 2000, over half the Fortune 500 companies have dropped off the list or shut down entirely due to digital disruption. It has been aptly said that companies that do not understand the importance of data management will find it extremely difficult to survive in the modern digital era. Data is going to be the biggest differentiator for businesses in the years to come. Enterprises that can unlock value in this data avalanche and use it to their strategic advantage will win. Big Data is recognised as one of the most important areas of the modern data tsunami and rapid technical innovation in the Hadoop ecosystem is going to make managing this data easier. Enterprises need to ensure that they are ready to leverage Hadoop, advanced analytics and AI on Big Data to stay relevant and profitable, and to gain competitive advantage.


