

Web robots, also known as Web crawlers and Web spiders, traverse the Internet to extract various types of information. Web robots can be used for legitimate as well as malicious purposes. Read more about them and make a simple robot of your own by following the directions given in this article.
When we come across the term ‘robot’, most of us think about the hardware robots that are replacing humans in doing various tasks at an alarming rate. Some of us may even have this vision of robots playing badminton, serving food, etc. According to software entrepreneur and futurist, Martin Ford, it is estimated that around 75 per cent of the work carried out by humans nowadays will be taken over by robots or machines by the end of this century. I am sure many of us have probably seen all that robots can do in Terminator and other such Hollywood movies. So if robots can carry out all such physical activities, then can a robot click on a Web button, Web check box or enter different input values in an input box? Certainly, it can perform all such tasks as well, and we call such robots Internet bots or Web robots.
A Web robot is simply a software application (or a set of programs) that traverses any Web application and performs various automated tasks. Though these robots can perform various tasks over a Web application, they are widely used to perform repetitive tasks, which they do much faster than if performed manually. Web robots, also referred to as Web spiders or Web crawlers, are nothing but scripts which retrieve information from different Web servers, analyse them and then file them at a speed that is many times faster than the rate humans would perform the same task. We should not be surprised to learn that more than half (52 per cent, according to Imperva) of all the Web traffic is actually enabled by Web robots, as most visitors to websites are not humans but Web bots. They are referred to as the worker bees of the Internet. Some of the Web bots help in refreshing your Facebook feeds continuously whereas some, like Googlebots, help us in figuring out how to rank different Google search results. Web bots make use of scripts to interact with different Web applications. Hence, we can develop Web robots using different open source scripting or programming languages like Perl, Python, C, PHP, etc.
All of these languages allow Web bot developers to write scripts that can actually perform different procedural tasks such as Web scanning, Web indexing, etc. Web bots can be made to perform many other different types of tasks with the help of these scripts and, hence, they are categorised based on the kind of actions performed by them on any Web application. There are malicious Web robots as well, which are used by hackers to perform diverse tasks on the Internet by installing some malicious files. Web robots make use of instant messaging, Internet Relay Chat or other Web interfaces to communicate with other users of Internet-based services. Internet Relay Chats also provide help services for any new user by lurking in the background of any conversation channel and commenting on some of the phrases uttered by users (based on pattern matching).
Different types of Web bots and how they are used
Web bots can be used to perform both legitimate and malicious tasks. Depending on the application for which a Web bot is used, it is classified into the following categories.
Legitimate Web robots: These perform legitimate actions on a Web application. They save a lot of time and effort for users. If the same task was performed manually, then it would have taken much longer time. These types of Web bots actually serve a purpose and act as time savers for different applications. They are broadly categorised as follows:
1. Spider Web robots: These are used by different search engines to explore different Web pages for organisation, content and linking. They have got certain criteria for indexing, based on which they determine the ranking of different Web pages within the search results. Such types of Web robots are used by Google and are called Googlebots.
2. Trading Web robots: These traverse or ‘spider’ different online auction sites in order to locate the best deals on any specific product or service. In such scenarios, a trading Web robot is used for commercial gain. These robots are also helpful in doing a complete analysis of different online commercial applications and provide users the best deals. Trivago, an online hotel booking Web application, uses such bots to display the best hotel deals.
3. Media Web robots: These are used to provide the latest news updates, weather conditions, sports news, currency exchange rates, etc. They are also used as censors in different applications that run instant messenger programs and chat rooms. Such Web bots are widely used by different online messenger applications like eBuddy, IMO, etc.

Malicious Web robots: Malicious Web robots are a collection of such bots, used in different ways to perform some malicious act or network security breaches. Such bots are widely used by hackers all across the globe.
1. Spam Web robots: These collect different data from various forms that are filled online. They are also used for spreading advertisements with the help of pop-ups. Different advertisement firms also use them for collecting email addresses of people to spam them with advertisements.
2. Hacker Web robots: Hackers use these to crawl around the Internet and thus find the vulnerabilities in different websites and online applications so that they can be exploited for malicious purposes.
3. Botnets: These are actually the networks that different hackers set up online by using zombie computers in order to perform various malicious acts such as the denial of service attacks. Zombie computers are those that have been taken over by a hacker without the owner’s knowledge.
4. Download Web robots: These are used to forcibly download any specific Web page that the hacker wants the surfer to see instead of the one that the surfer requested. We all have experienced a scenario in which we are left with no other option but to click on a link so that the particular Web page gets downloaded.
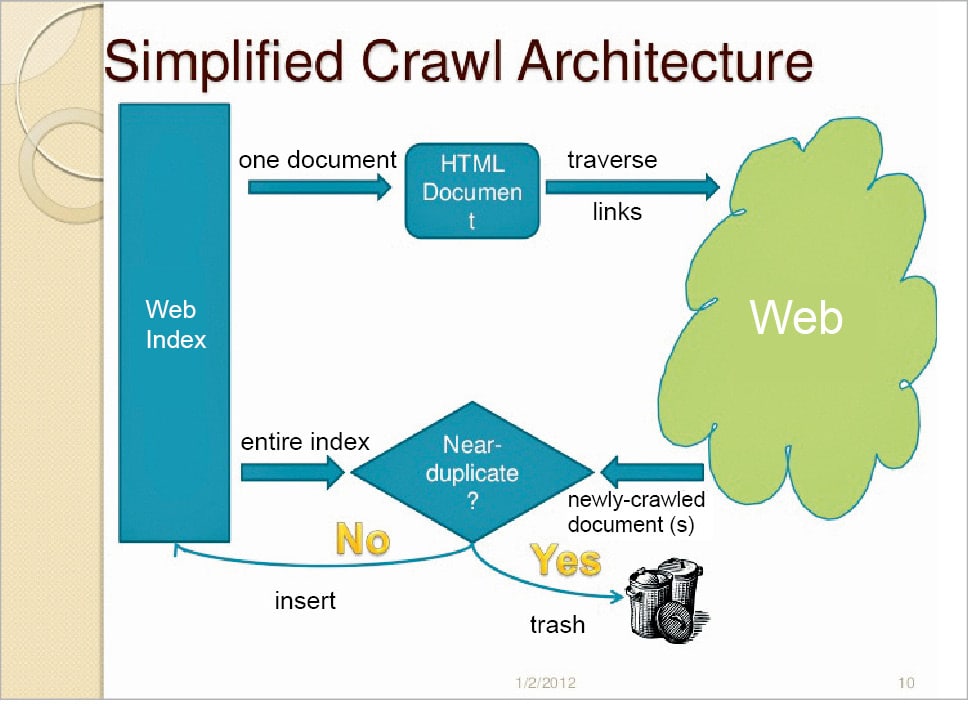
What should be considered before creating a Web robot
Before developing a Web robot, we need to carefully analyse the task we want it to perform. Here are a few general considerations that need to the looked at before developing a Web robot.
1. Analysis of the task or set of tasks that we want Web robots to perform for us. It’s good to use Web bots for repetitive tasks or anything that takes a lot of time when done manually, compared to when it’s done automatically.
2. The sequence of steps that the Web robot needs to take so that the task is completed in the minimum amount of time needs to be well planned. It helps to obtain an efficient, error-free and effective program.
3. Check if the Web bot requires manual intervention or if the task can be fully automated.
4. Properly analyse the scripting or programming language that best suits the development of the Web bot, which can perform the specific task in the least time and with minimum cost and effort.
5. Check if the Web bot’s requests, edits or any other actions need to be logged.
6. Check if the Web bot needs to run inside a Web browser or just be a standalone program.
7. If the Web bot runs on a remote server, check if it is possible for other editors to operate it.
Developing a small Web bot, free of cost
After we have made our considerations, we are good to go ahead with the development of the Web bot. Let’s develop a small one, using Python scripting in order to scan a specific Web page.
You need to have the following installed on your system:
- Python 3.x or above
- Any text-editing application such as Notepad, etc
Now follow these steps:
- Open any plain text editing application, like Notepad, which is included with Microsoft Windows, where a Python script for the Web robot application can be written.
- Initiate the Python script by including the lines of code given below; the reason for including specific lines in the code has also been mentioned as ‘comments’.
# importing required library files from html.parser import HTMLParser from urllib.request import urlopen from urllib import parse # Creating a class called LinkParser that inherits some methods from HTMLParser class LinkParser(HTMLParser): # adding some more functionality to HTMLParser def handle_starttag(self, tag, attrs): # checking for the beginning of a link as they are normally present in <a> tag if tag == ‘a’: for (key, value) in attrs: if key == ‘href’: # grabbing new URL and adding the base URL to it so that it can be added to collection of links newUrl = parse.urljoin(self.baseUrl, value) self.links = self.links + [newUrl] # Function to get links that spider() function will call def getLinks(self, url): self.links = [] self.baseUrl = url # Using the urlopen function from the standard Python 3 library response = urlopen(url) if response.getheader(‘Content-Type’)==’text/html’: htmlBytes = response.read() htmlString = htmlBytes.decode(“utf-8”) self.feed(htmlString) return htmlString, self.links else: return “”,[] # spider() function which takes in an URL, a word to find, and no. of pages to search through def spider(url, word, maxPages): pagesToVisit = [url] numberVisited = 0 foundWord = False # Creating a LinkParser to get all links on the page. while numberVisited < maxPages and pagesToVisit != [] and not foundWord: numberVisited = numberVisited +1 # starting from the first page of the collection: url = pagesToVisit[0] pagesToVisit = pagesToVisit[1:] try: print(numberVisited, “Visiting:”, url) parser = LinkParser() data, links = parser.getLinks(url) if data.find(word)>-1: foundWord = True pagesToVisit = pagesToVisit + links print(“ **Success!**”) except: print(“ **Failed!**”) if foundWord: print(“The word”, word, “was found at”, url) else: print(“Word never found”)
The many applications of Web robots
1. Chatterbots allow people to ask questions and formulate a proper response.
2. Web bots help in handling many tasks such as reporting weather, sports scores, zip-code information, etc.
3. They are used to develop different messengers like SmarterChild on AOL Instant Messenger, etc.
4. They are widely used for Web page scanning and indexing.
5. They can report real-time vehicle locations for the trucking industry.
6. They can also mimic the tasks performed by a psychiatrist, if loaded with many responses.
7. They report air quality.
8. Gaming bots are used for many gaming applications as well.
9. Auction-site Web robots make the process of auctioning easier.
Advantages and disadvantages of bots
Advantages:
1. Help in performing different actions on Web applications at a much faster rate than when the same task is done manually.
2. Help in retrieving the data required from large sets in the least possible time.
3. Can be quite helpful for different site owners to create additional traffic if the site is being included for some index.
4. Web robots are always more reliable and efficient in the actions that they perform as compared to when the same task is done manually.
Disadvantages:
1. There are temporary denials of service, at times, to other visitors reaching a site, which is caused by heavy bursts of page downloading. Visitors may not be able to access site pages at normal speed, or in some extreme cases, not at all, since a robot is busy downloading the pages in a heavy burst and consuming most of the Web server resources.
2. The use of Web robots also results in wastage of bandwidth, as some of the contents that these bots download may not be useful to a person at a later time; hence, the chances of downloading content and then throwing it away is higher. This can ultimately add to bandwidth loss.
3. Different malicious web bots are used by hackers to check for vulnerabilities in the Web system, and they exploit the same for different malicious activities.
4. Malicious Web robots are also used to spam emails of users in order to retrieve user information.

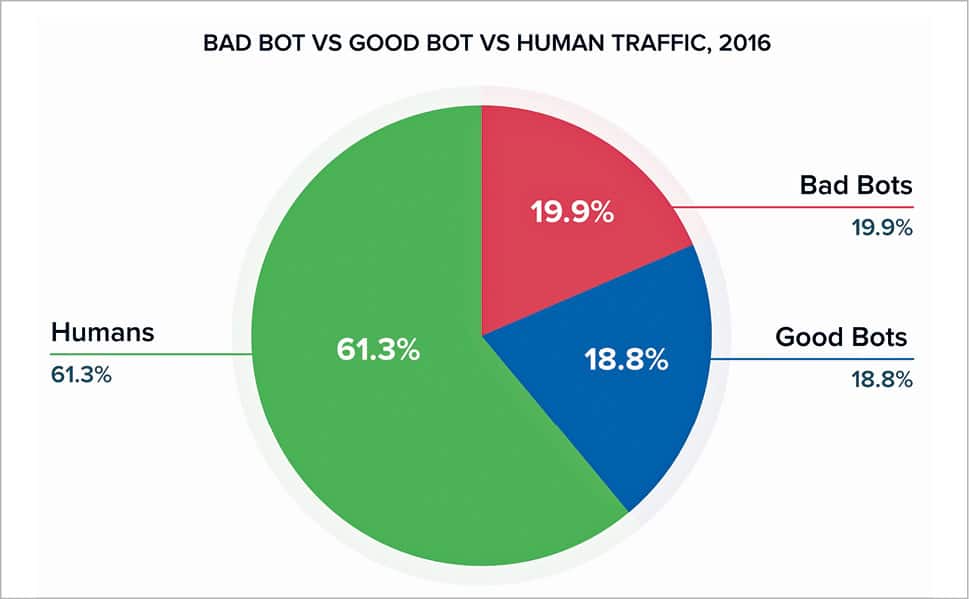
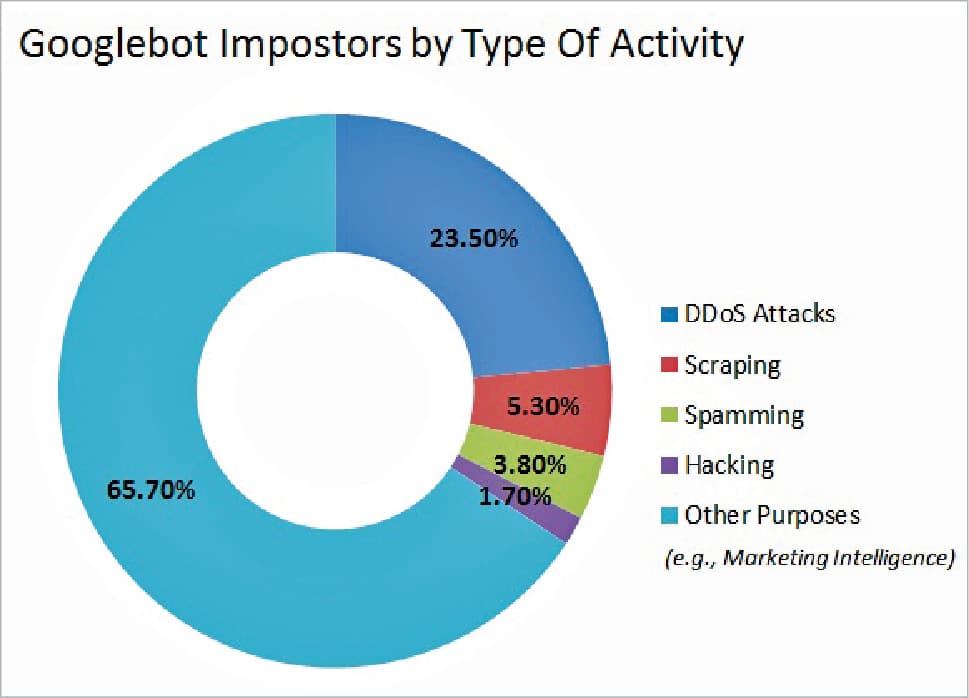
Preventing the problems associated with Web bots
We can prevent some of the issues that arise from using Web bots by taking the following precautionary measures.
1. Check if we are actually being visited by Web robots often enough before taking any other measures: We can check if robots are visiting our pages by examining our Web server log files. We can look in the user agent field for unusual names, the frequency of their visits and also for the type of files that are being retrieved.
2. Use the meta tags, robots.txt file and other ways to suggest to robots how your site should be indexed or not indexed: Try suggesting to the robots as to how you would like your site to be indexed or downloaded.
3. Convert all time-consuming scripts to the static pages if possible: It takes longer for any Web server to execute the scripts that generate Web pages than to serve different static HTML pages. Hence, it is less likely that your server would get a denial-of-service when Web robots download static files in heavy bursts.
4. Check if a possible Web robot requested the script before performing any time-consuming functions: If you have to use scripts on your website, check if any possible unfriendly Web bot called the script before going into time-consuming parts of the scripts.
5. If any particular IP address is continuously causing problems in spite of taking the above steps, then consider limiting access to the server: If we have positive proof that any particular IP address or class of addresses is causing problems to your Web server, then try contacting the owners of such Internet connections. If all this fails, you may consider excluding such addresses from your Web server.
6. Use different server-specific components: If you still have severe problems in avoiding unfriendly Web robots, write server-specific components. This is where you write an extension to your Web server which would dynamically verify different properties of calling programs to check for possible Web bots.


