





























































We live in the big data era where a massive amount of real-time data is getting generated by various sources including business and social data from different domains like healthcare, finance, banking and Internet of Things (IoT). Generally, streaming data pipelines are implemented using highly scalable messaging systems such as open source Kafka and data processing engines like Storm, Spark or Flink. These data processing engines are used for data processing involving data filtering, manipulation, aggregations, categorisations and other features. The output of such data processing engines are stored in a NoSQL database like Cassandra, HBase and MongoDB, and it can be used to generate analytical reports. Kafka has emerged as the perfect fit in such streaming data pipelines as it is a fast, horizontally scalable, distributed in nature by its design, supports data partitioning and replication.
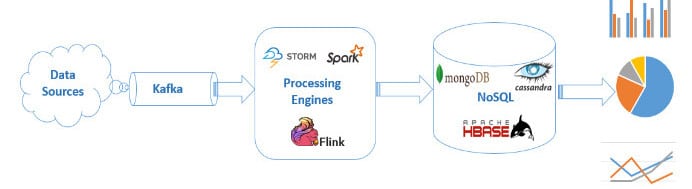
As a part of performance engineering, we always need to benchmark our entire streaming data pipeline and need to ensure that it is able to process at high scale.
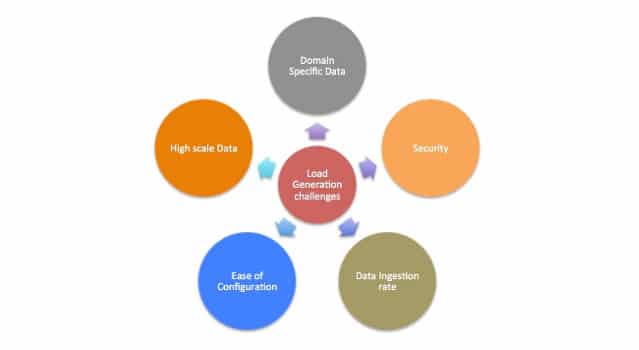
When it comes to Kafka load generation, we always face some vital challenges and there are open source tools that can solve these challenges.
Challenges with Kafka
Business specific data: Every business solution implemented using streaming data pipeline has its own datasets and its own data representation formats. Formats may include JSON, XML, CSV or any other custom text format — even some solutions may also send serialised objects. For instance, share trading data pipeline may include stock specific data (stock, price and firm) in JSON format whereas data pipeline collecting world temperature may include temperature specific data (temperature, long, lat and location) in XML format.
Simulate data source at high scale: Streaming data pipelines are generally designed to process a large volume of real-time data generated by different data sources. Some data pipelines are targeted to process a million of events per seconds.
Security: Kafka provides different security mechanisms to ensure data security. For instance, authentication using Kerberos SASL, SSL/TLS and authorizations using ACL technologies.
Controlling data ingestion rate: Some streaming data pipelines are designed to handle desired data ingestion rate while some are developed to handle data spikes during peak hours. For example, shared trading data pipelines have very high load during business hours. Kafka load generators can help to simulate scenarios like throttling ingestion rates, generating ingestion spikes, load rate variation over the period of time.
Ease of configurations: Sometimes we need to tweak Kafka producer parameters to get better throughput as batching, data compression, network buffers, buffer memory, linger time are critical aspects at Kafka producer and make a significant impact on Kafka performance.
There are some load generation tools available to help us solve the challenges mentioned above. These tools have distinct features to meet diversified requirements.
Kafka built-in benchmarking utility: If you are looking for just benchmarking Kafka cluster, then this is the most useful utility. But it cannot satisfy the need where we need to generate load on entire streaming data pipeline with business specific data in a specific format.
KafkaMeter: This is another Kafka load generation JMeter plugin. It allows you to benchmark Kafka and can control throughput rate. However, this tool does not support some security features like Kerberos authentication and also when it comes to business specific data it involves some development activity. Also, by default, it generates only tag serving domain related data.
Pepper-Box: Using Pepper-Box we can generate business-specific data on entire streaming data pipeline at high scale. It can be used as JMeter plugin hence we can use all JMeter features. It provides an easy interface to configure Kafka producer tuning parameters and supports all Kafka security mechanisms such as SASL and SSL/TLS.















Well written! Thanks for sharing the knowledge!