

OpenShift is a next-generation container based, secure and scalable platform for rapid application development. Let’s first understand the way it works, and then use it to build a simple application.
OpenShift is a Platform-as-a-Service by Red Hat, which provides a quicker way to develop, deploy, monitor and scale applications in a secure and on-demand cloud. OpenShift has been built with only one goal, which is “To quickly build an application and make your clients happy.” By using OpenShift, developers can focus on the core logic of an application rather than configuring and maintaining it.
OpenShift became famous after v2.0. Currently, it runs on v3.0, which is the next-gen PaaS that uses Docker containers and Kubernetes. In the next section, we will look more closely at all these terms. OpenShift v3.0 is different from OpenShift v2.0, so we will not go deep into v2.0 but focus more on v3.0.

Let’s study some of the basic terms before trying to understand the OpenShift stack.
Virtual machines vs containers: Virtual machines contain all the binaries, libraries and application code along with the guest OS, which will be in Gbs.
Containers contain the application and related dependencies. They share the same kernel with other containers, and every container runs as an isolated process in user space on the host OS.
By comparing virtual machines and containers, we can get more clarity on how containers differ from virtual machines.
Docker: A Docker container is a piece of code in a file system which contains everything needed to run it, such as libraries, application code and system tools. Basically, it provides everything that can be installed on a server. The advantage of using Docker containers is that they can run anywhere, in any cloud, and with any infrastructure.
Kubernetes: This is a tool/system that is used for automating containerised applications, and its functions include deployment, scaling, load balancing and management.
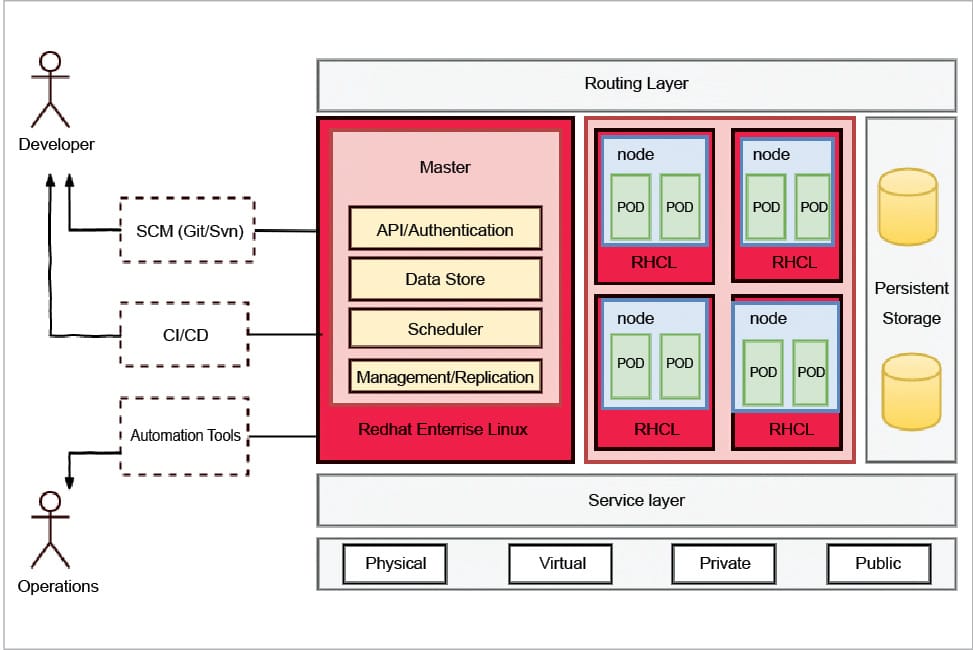
OpenShift stack
Figure 1 demonstrates the new OpenShift stack for v3.0.
- OpenShift v3 is built on RHEL 7, which has more capabilities compared to RHEL 6. Also, it is a part of the Atomic project, which was launched to enhance Linux host capabilities and optimised container based application environments.
- Red Hat is contributing to a project called libcontainer, which provides standard APIs for defining containers like network interfaces, namespaces, cGroups, etc. So OpenShift uses Docker libcontainer, which is lightweight and provides isolation through OpenShift gear, which is the main focus of developers. OpenShift v3 cartridge enables customers to leverage any application component packaged as a Docker image, which also enables users to share and access container images globally (in the market place).
- xPaaS services in OpenShift provide capabilities like JBOSS portfolio, SQL or NoSQL databases, cache, log managements, monitoring tools, message brokers and many more functionalities.
- Any application in OpenShift contains multiple gears (each gear has memory, bandwidth, CPU and disk allocated to it). We can either use single or multiple gears to create applications. Sometimes, one application is part of one gear and the other application is part of another gear, so to manage them we need an orchestrator. OpenShift broker manages orchestration and scheduling activities. In OpenShift v3 we leverage the advantage of Kubernetes, which is used along with an OpenShift broker to handle large scale cluster based applications.
- The OpenShift dashboard is user-friendly, and any kind of application development in Java, PHP, Python, Node.js or other supported languages is much easier and quicker than in other PaaS service providers.
- OpenShift has wide community support as Red Hat is actively participating in many open source projects, and OpenShift is the combined effort of all those communities.
OpenShift v3.0 architecture
Figure 2 demonstrates the overall architecture of OpenShift v3.0.
As we have seen in Figure 1, OpenShift v3.0 follows the layered approach that leverages the benefits of Docker and Kubernetes. OpenShift v3.0 focuses more on how we can combine different services and compose an application easily. For example, in v3.0 we install Python, push code and then add MySQL.
However, OpenShift v2.0 provides configuration flexibility after composing all components. In v2.0, the application is used as a separate object, which is removed in v3.0 to provide flexibility in terms of combining various services— like different containers can reuse the same databases and expose them directly to the edge of the network.
OpenShift provides the functionalities listed below:
- Code management, build management and deployment
- Application management (elasticity, scalability and load balancing)
- Managing images in scale systems
- Team and user management for any organisation
The OpenShift architecture is made up of different small components, which run on top of the Kubernetes cluster where data about all the objects is stored in etcd (it’s a master state—other components will look for this state and if any changes occur, then those components will change themselves into the desired state). It is also configured for high availability and deployed with 2n+1 peer services. REST APIs are used for communication between core objects. The controller reads those APIs and makes changes accordingly, to different objects. For example, when the request comes for build from the user side, a build object is created. The build controller then sees this object and runs a process to perform that build. Once the build is completed, the controller updates the status via the REST API to the build object, and the user can see that the build is over.
OpenShift follows the controller pattern, which provides flexibility and extensibility. We can define the behaviour of the controller whenever any object is created. Basically, it’s business logic—it takes the controller and can also leverage the benefits of APIs to do any kind of automation and optimisation using scripting languages. We can also schedule cron jobs for any specific administrative tasks.
The controller should be in sync with the system and users, which happens due to even streams that push data from etcd to REST API and controller, so that the controller can quickly perform the required actions. In a failure scenario, the controller should resync all the data and resume the tasks accordingly.
OpenShift uses OAuth tokens and SSL certification for authorisation. A client typically makes API calls using a Web console or client program, and uses OAuth tokens for all the communications. Infrastructure (nodes) validation is done by client certificates generated by the systems that own the identities. Components inside containers use tokens to connect the APIs.
The OpenShift policy engine handles the authorisation part by creating different policies for a set of users and groups. Whenever any service account or user tries to perform an action, the engine checks for its identity before approving it.
Every container associates with the service account in the cluster. We can associate secrets (this is a service that handles all the passwords) with the service account, and automatically deliver these into the container. This provides the infrastructure the flexibility to manage secrets and perform different actions like pushing images, and also allows the application code to benefit from the secrets.
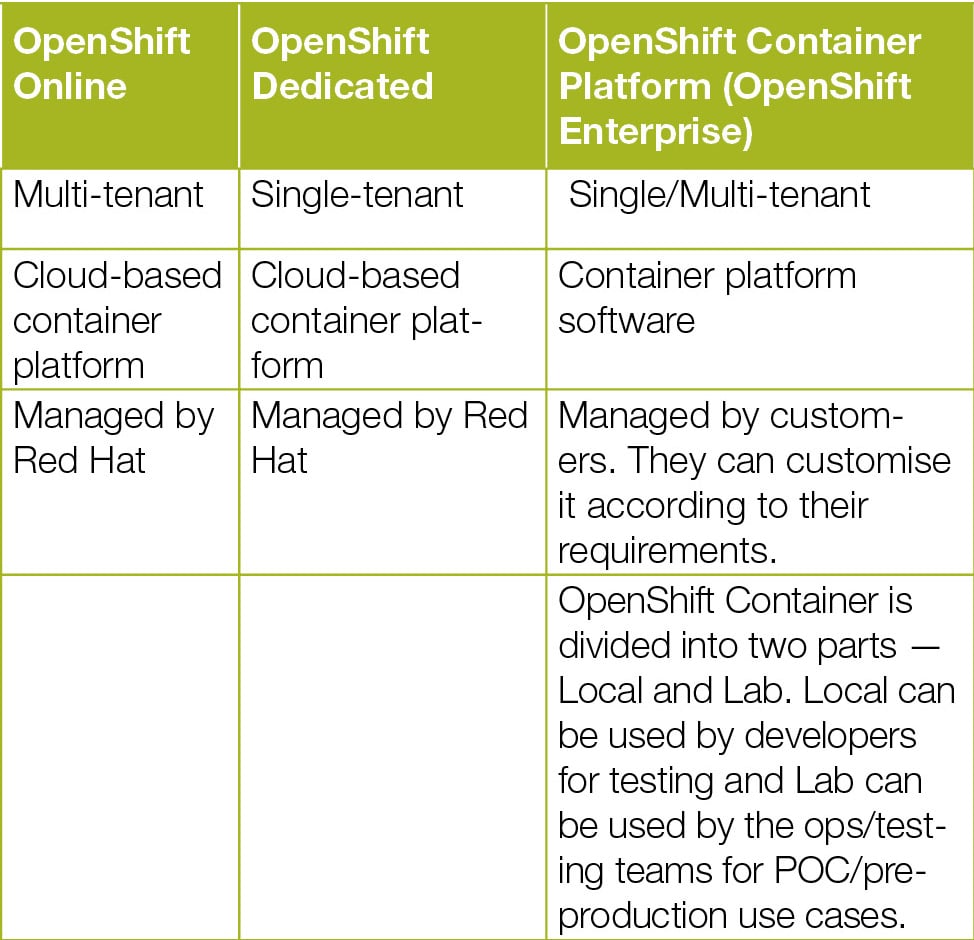
OpenShift flavours
OpenShift currently comes in three flavours, as indicated in the table below.
Pricing
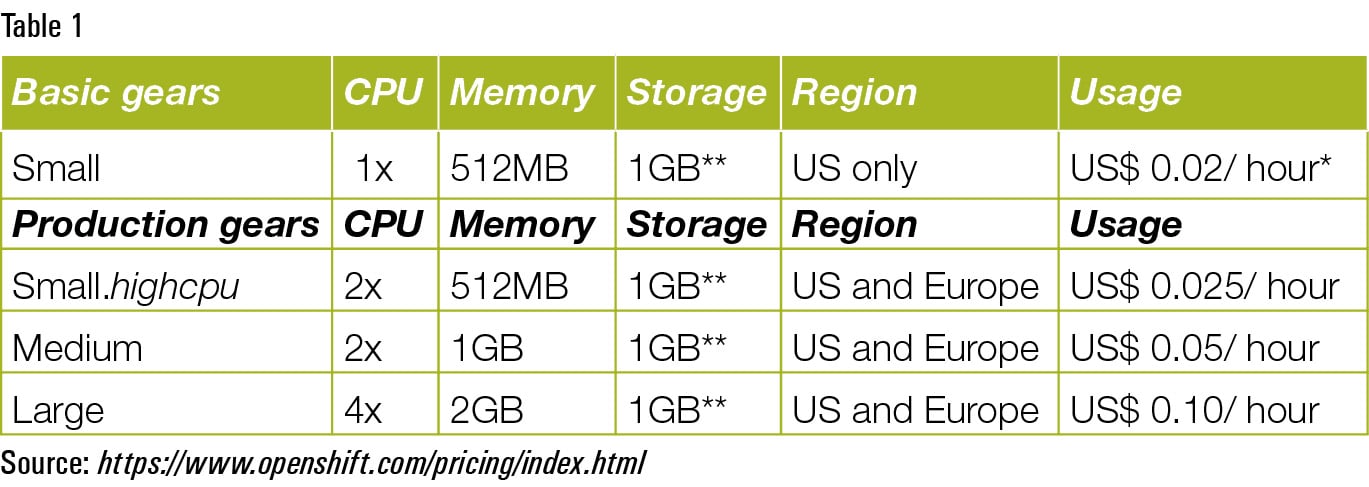
There are three plans available for OpenShift (see Table 1).
1. Bronze Plan: Free + pay as per use + private SSL support, team management, no application idling.
2. Silver Plan: Pay as per use + phone/ticket based support for US$ 20/month + 5GB extra storage for every gear.
3. Developer Preview Plan: Free plan available for preview without any extra support.
* All plans include three small basic gears for free.
** In the Silver plan, each gear includes 6GB of space.
** Bronze and Silver plan users can add up to 30GB of additional storage to individual gears for US$ 1.00/GB/month.
In India, we can adopt free plans, as these are accessible worldwide, but Silver and Bronze plans are available only in North America and Europe.
For more details, visit the OpenShift pricing page which covers all the details mentioned above.
Deploy an application using OpenShift Online
Let’s use the developer preview plan to deploy the application using OpenShift.
A long time back, I created an account on OpenShift v2.0, which had a free quota available for more than a year. After August 1, 2016, the OpenShift Community is not accepting new registrations for OpenShift v2.0. They strongly recommend that new users start with OpenShift v3.0.
The OpenShift v3.0 developer preview plan has only a 30-day trial period and once it expires, all your data is deleted; so if you are using a preview plan, then please migrate the data before the trial period ends. As I have already created an account in OpenShift v2.0 long back, my application is still running, but once OpenShift v3.0 matures, all OpenShift v2.0 users will have to migrate their applications to OpenShift v3.0.
For the OpenShift v3.0 developer preview plan too, you need to wait for approval, as currently very limited resources are available. Based on the availability, you will be sent a mail and you will get access for 30 days.
Here is the step-by-step approach to creating an app in OpenShift Online.
Go to https://www.openshift.com/ and sign up. You will be asked for your GitHub account. If you don’t have one, create it first and then log in with this account.
Now you will be asked to authorise the application. Please do so.
Once this is done, check whether your request has been approved. I am getting messages saying that currently all resources have been allocated so I have to wait for my turn.
As I have already created an account in OpenShift v2.0, we will use it to see how we can leverage the benefits of OpenShift. Users who have already created an account before August 1, 2016, can follow the procedure shown below and deploy an application.
Go to https://www.openshift.com/ and then to My Account, and select the OpenShift Web Console in the Openshift v2.0 platform or New Gen Web Console in v3.0.
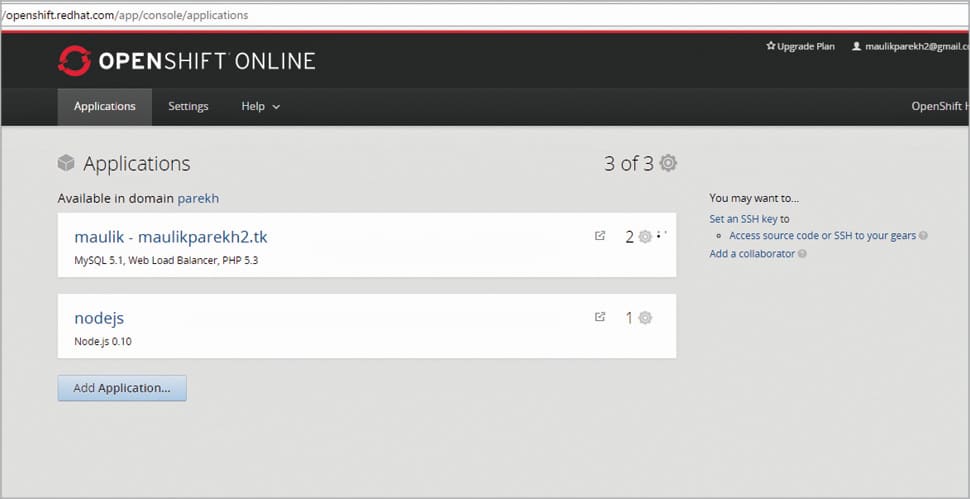
You will see the application page, where all the running apps are listed. I have already created apps for testing.
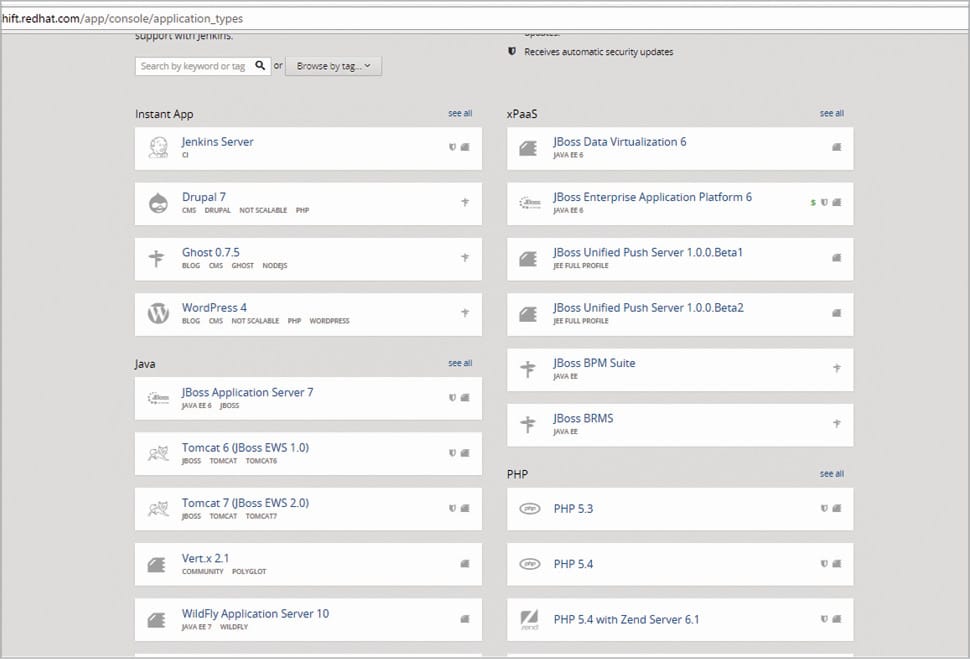
Click on Add application, and you can see a list of cartridges (managed runtime for applications) supported by OpenShift v2.0.
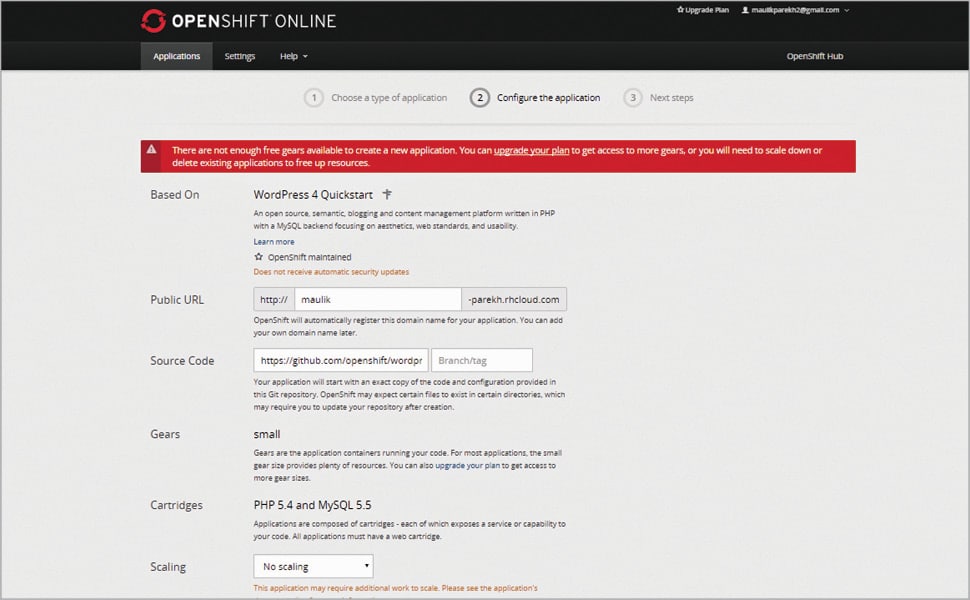
Based on the application’s requirements, select the appropriate cartridges. Currently, I have chosen WordPress, as I want to create Web applications with it.
Provide the domain name for the public URL. OpenShift will automatically register this domain name as a public URL. Leave all other options as default, and click on Create application.
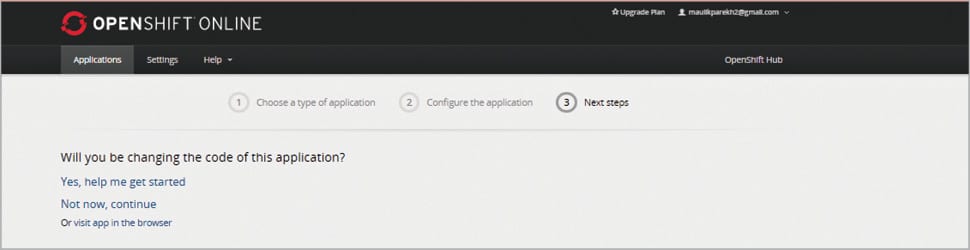
Once the application is created, it will give you two options to change its code—either now or later. Choose Later and continue.
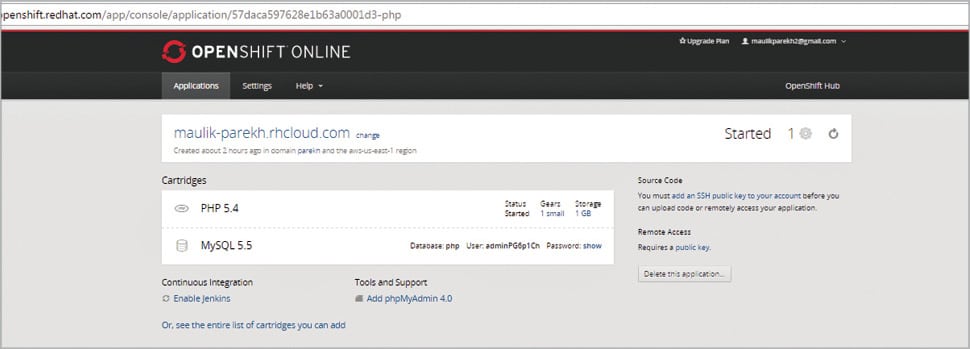
Now the application is ready with MySQL 5.5 and PHP 5.4. The application’s URL in my case is maulik-parekh@rhcloud.com.
Click on this URL and you can see that the WordPress installation has started. Enter the application’s details and click on Install WordPress.
You will see an Installation successful message, so click on Login and start using WordPress. You can choose any theme and activate it. Modify your contents accordingly. So this is how we can deploy a cloud based application on OpenShift v2.0 using WordPress.
WordPress is easy to learn and people who don’t know how to create a website on it can search the Internet—there is a lot of material available on the topic.
In later articles, we will look at how we can deploy Java, Python and Node.js based applications using OpenShift. Since, for v3, the free trial is limited to 30 days (which was not the case with OpenShift v2.0), you could also pay to enjoy the benefits of a next-gen container based PaaS.


