





























































 Scalability is an integral part of the software design process. Hence, applications must be designed such that their components can be de-coupled and then scale independently. The concept of scaling also requires one to design applications that have no footprint on the application server. This helps the application to quickly allocate/de-allocate servers.
Scalability is an integral part of the software design process. Hence, applications must be designed such that their components can be de-coupled and then scale independently. The concept of scaling also requires one to design applications that have no footprint on the application server. This helps the application to quickly allocate/de-allocate servers.
“It was the best of times; it was the worst of times.” These opening lines in author Charles Dickens’1859 classic called ‘A Tale of Two Cities’ pretty much sum things up in our case. The time when you start getting an unexpected boost in the business, makes it a great period in the life cycle of the Web app. At the same time, you will experience times when the performance of your application drops drastically and the server crumbles. This is not a desirable state to be in when your business is growing. You have to get to scale — not only being able to scale things up when the business is up but also scale down when the load goes down.
“It won’t scale, if it’s not designed to scale.” This statement is true with any solution built on this planet. The ability to scale and be able to handle large amounts of traffic is something one needs to keep in mind while building solutions. This requires less effort if you focus on certain do’s and don’ts. In this article, we will primarily focus on certain challenges you may face while you consider incorporating the scalability factor into your Web apps. We will also cover architectural changes that might crop up while you adopt a specific design approach. The cloud is an integral part of addressing scale, and we will discuss a few factors that could make your solution cloud-ready within the ambit of open source technologies.
What is scalability?
What does the term scalability mean? Is it related to performance, availability, the reliability of the solution or is it related to cost management?
Scalability is the ability of an application to be able to scale to different parameters like:
- The ability to store large amounts of data when it needs
- The ability to perform a large number of transactions
- The ability to handle huge traffic surges
The new age tools, however, also consider cloud computing and help to reduce costs while keeping scalability in mind. They helps in optimising the costs when the solution reaches high scale thresholds.
Making scalable Web apps
Let’s take a staged approach towards making a scalable Web application. Let us take a simple educational website that works like a portal, hosting articles and videos uploaded by faculty members, meant to be read and viewed by students.
Imagine this solution as a mix of YouTube and SlideShare, along with search capabilities, where students and faculty can upload and consume the content.
The most important requirement is to provide a stable and scalable platform to deliver the content.
To summarise the important requirements, the application should have the following:
1. The ability to store documents and videos of different sizes and even larger files up to a few GBs.
2 The ability to query and view the documents/videos – there must be a player to render/play the documents or videos.
3. There ought to be no limit on the number of documents or videos the Web application can store.
4. There needs to be low latency for documents or videos to download.
5. It should be cost-effective.
We’ll take the approach of a simple Web application, with a front-end and a back-end. Let’s explore situations that may arise, and scale our application by using certain tools that will result in inherent changes to the app.
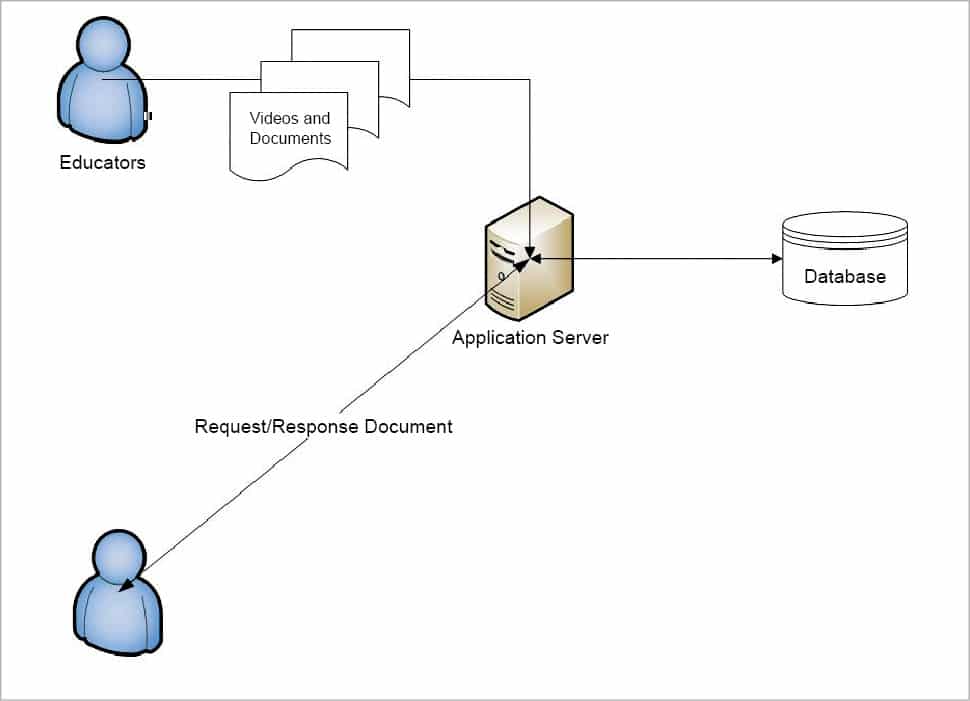
The deployment architecture of our Web application is shown in Figure 1.
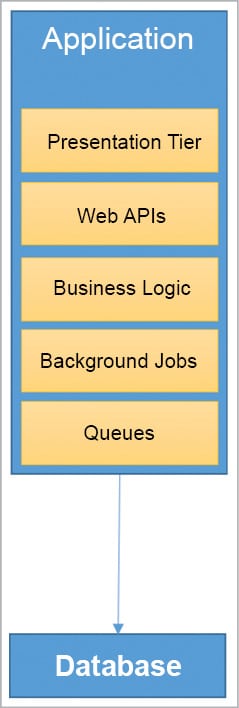
The application has the following tiers:
1. The UI tier, which will have the presentation logic.
2. The Web API tier, which allows the application to integrate with third parties or app interfaces. This is especially important to integrate with mobile applications, third party content providers or external websites, as it allows maximising the reach of the application’s content.
3. The business logic will consist of all the validation and logic for data processing. It is the soul of the entire application and all of the above tiers are dependent on this one.
4. The background jobs will perform all the heavy duty tasks without impacting the mainstream application’s performance. In our example, whenever a user uploads the content, there can be many other background tasks that do the batch jobs like generating previews, creating thumbnails, indexing documents, sending notifications, emails, etc.
5. In order to streamline the load pertaining to certain requests, one can use queues (asynchronous mode), e.g., the process of printing the course completion certificates for students could be a good candidate for queues, wherein all jobs that need to be printed are in queue and the program can pick one after another to print the certificates.
Figure 2 shows the typical solution architecture of the Web application.
We will put down a few parameters while addressing the scalability of this solution. These are:
1. Ensuring that the application can handle the traffic surges.
2. Ensuring that the heavy duty processing caused when uploading content will not impact the experience of the content consumer.
3. Ensuring there is no adverse impact on existing logged-in users when adding an additional server to handle more load.
4. Fulfilling the requirement of storing large amounts of data (documents or videos).
5. Addressing low latency when downloading videos/documents.
6. Tackling cost savings while scaling out.
7. The background jobs will be working in a multi-threaded environment so one has to ensure that all such jobs are completed on time even with huge amounts of data to be processed.
We will address each of the above scalability requirements using the best practices in that area.
Best practices in Web app scalability
Practice# 1: Ensure that an application can handle traffic surges by scaling compute resources.
The solution is to scale compute resources.There are two types of scalability – vertical and horizontal.
Vertical scalability is when the application is running in one server and the server’s resources are increased, e.g., increased RAM, a better CPU or a much bigger HDD. All such resources can lead to the better performance of an application, but vertical scalability has the following drawbacks:
- Downtime is required in order to scale up the machine.
- With all eggs in one basket – if something happens to this ultimate machine, the business is at risk!
- How much can a single machine scale anyway? There are limits to scale the resources in a machine.
Horizontal scaling on the other hand is bliss — one can put in identical resources (in this case, identical machines with the same application server) together and let them handle the traffic. Whenever traffic grows, just add up more identical resources together and let them handle the traffic via load balancers.
To segregate the load to application server clusters, the load balancer will be required in the front of the cluster, which will balance the load based on certain algorithms like Round-Robin, or IP Affinity, to direct the traffic towards the machines behind the load balancers. There are many open source software based load balancers. A few popular ones that are easy to work with are Apache (a module for load balancing is available as mod_proxy_balancer), Nginx (also has a balancer built-in), Pound, Squid (which is also a proxy server), or Inlab.de’s Balance.
Advantages:
1. Scale up as required by adding more compute resources and reduce those resources to scale down.
2. Cost saving: Scaling on a need basis and using optimum compute resources ensures that spending too will be optimum on compute resources.
Disadvantages:
1. Deploying and switching builds becomes a concern in a scaled out environment. Hence, a good DevOps practice is the need of the hour (one may have to use continuous deployment).
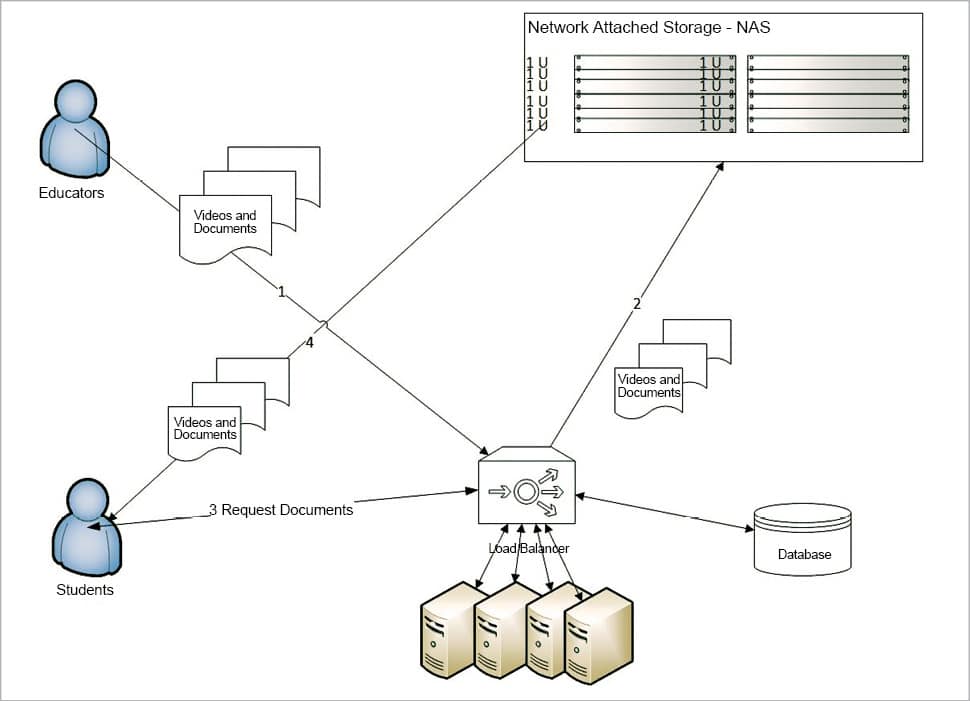
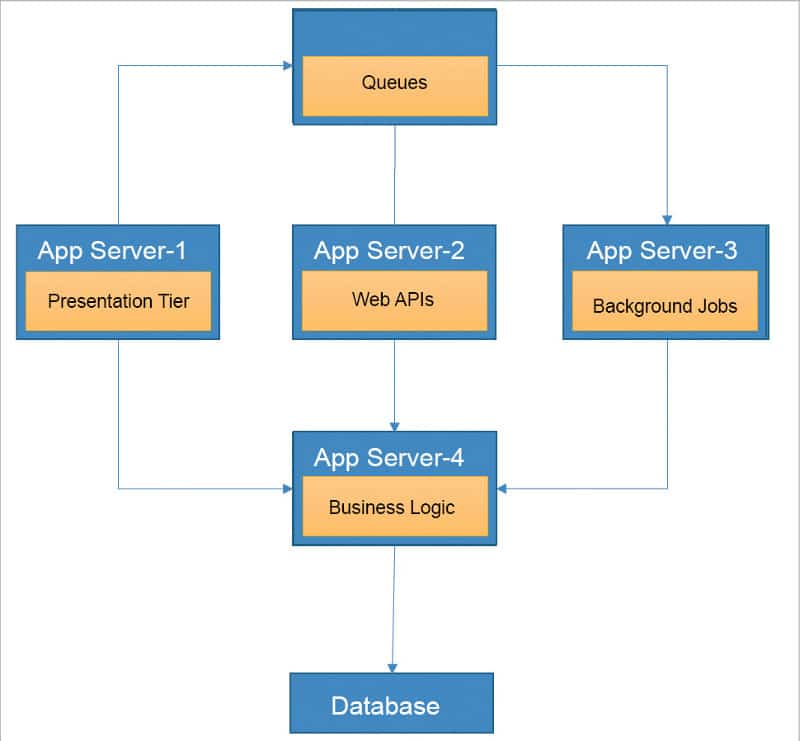
Practice #2: Ensure heavy duty processing while uploading content by the content producer and a seamless experience for content consumers, using ‘shared nothing architecture’.
To achieve this, we need to consider a multi-tier deployment of the application workload. Consider that every application component is deployed onto its own dedicated server, which helps each component to handle the user load separately. This will increase the robustness of the application and provide a better experience to the end user (content producer/content consumer).
Advantages:
- Selected components can scale independently as the load increases on the respective component.
- Division of the workload will lead to division of the user load, ensuring the application can handle the user load efficiently.
- Less resources will be required to deploy the specific component, resulting in a lower cost of primary servers and of additional servers (in case of scale-out).
Disadvantages:
- Managing multiple tiers/servers will be a challenge. This requires one to have better control over the deployed blueprint.
The architecture of the application in this approach is depicted in Figure 4.
Practice #3: Ensuring that retrieving frequently used data like the user’s session state is faster, and does not require too many round trips to resources like the database by using caching techniques.
In load balancing, whenever the server side sessions are not practical, the application needs to store the session state in some other data store, from where the sessions can be fetched quickly.
The options to store such session states could be:
1. Store it in the client side, in the form of cookies, or HTML5 storage APIs.
2. Store it in a database. Most databases offer to store session states, so use the feature.
Caches are based on the ‘Locality of reference’ principle; recently requested data is likely to be requested again. Every layer of the Web application architecture can have the caching of data or caching of static resources.
The most often used caches are at the front-end tier. The idea is to use them in close proximity to the front end or application logic to make sure the response to a request has the least hops possible.
The most popular caches are Memcache and Redis cache. These can be hosted on separate clusters and calls can be made to them using a particular protocol at a particular port. The cache cluster is expandable in its own sense. Most of the caches work on a key-value store basis and keep data in memory (RAM, usually), since the data is retrieved against a key.
Both Memcache and Redis can serve local as well as distributed caches. Many large websites like Facebook use Memcache clusters for their caching mechanisms (Reference: ‘Scaling Memcached at Facebook’).
For cloud implementations, one can choose between various options — either Redis, Memcache or proprietary protocol based caches.
Table 1 gives a comparative analysis of the above discussed caching technologies.
| Technology | Pros | Cons |
| Memcache | Key-Value O(1) Horizontal scaling is much easier |
Data persistence is not possible Max value: 1MB Max Key: 250 bytes |
| Redis | Offers replication Configurable data persistence Key/value: Up to 512MB |
|
| Cloud service caches | Choose from Redis/Memcache; Easily scalable |
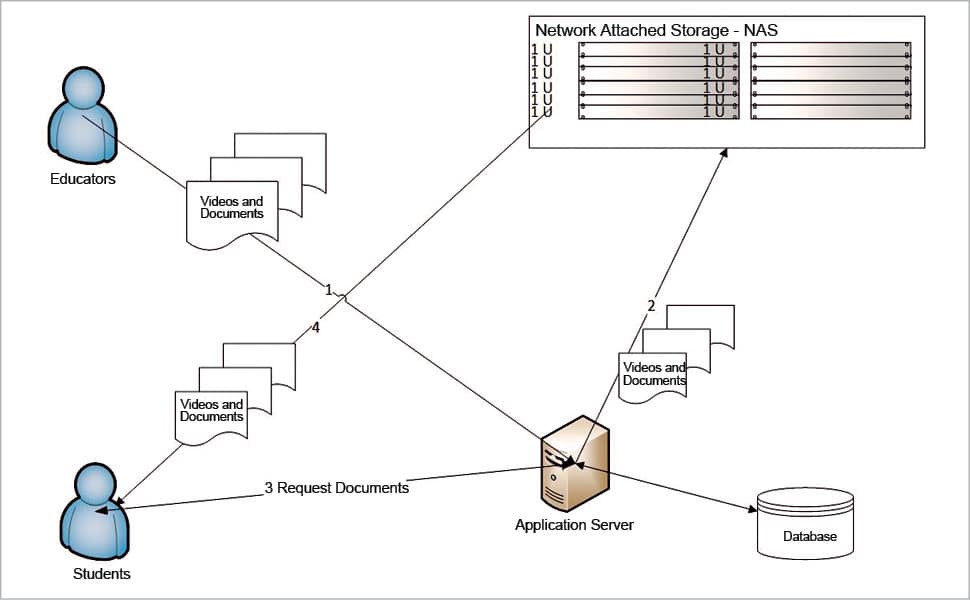
Practice #4: Store large amounts of content in a separate data repository, which can be scaled separately.
Scaling the storage thus is our concern at this point. The golden rule of scaling is ‘Decentralise to scale’.
So, at this point, let’s focus on decentralising the storage and taking it off from the monolithic application server approach. To do that, let’s start using a scalable storage which, if running in an on-premises data centre, could be a NAS (network attached storage). In this case, one can add more and more storage to a NAS to scale it independently. There are other open source implementations, too, that can be used for on-premise virtual appliances, like OpenStack Swift or CEPH.
Figure 5 shows what our architecture looks like after the above mentioned change.
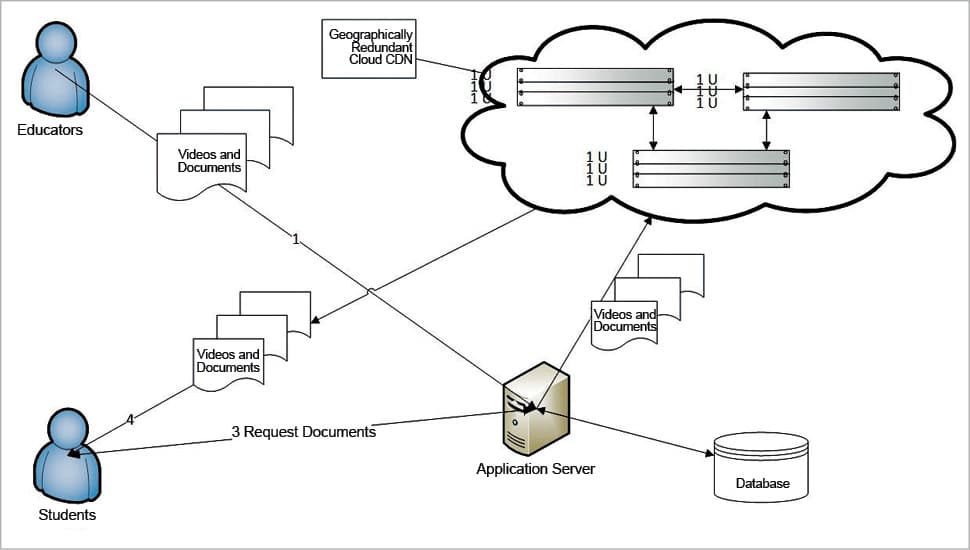
Practice #5: Ensure low latency while videos/documents are being viewed and used, by using geo-redundant copies of content in different geographies.
Having NAS will not ensure the reduction of latency while downloading the content. Even having cloud based storage will not ensure the same at the first go, unless it is configured to do so.
So the answer to low latency, which will also help in achieving high availability, is to go for geographically redundant storage copies, so that the requests coming from different parts of the world get served from the geographically nearest data centre. You can also consider using a CDN (content delivery network), which ensures low latency by keeping redundant copies.
Table 2 gives a comparative analysis of the above discussed storage options.
| Technology | Pros | Cons |
| Network attached storage | Easily scalable Resilient Data redundancy Data encryption User access control |
Need to buy more storage disks every time a Web app scales up Maintenance overheads |
| Cloud service storage/CDN | Easily scalable Pay-as-you-go Samba protocol (optional) Geographic redundancy Options to move to cold data stores |
Pay extra for redundancy |
However, you need to keep the following points in mind:
1. While working with cloud based storage, you pay for the data stored even if it is not used. This is called Cold Data. If the use case allows moving such data to a Cold Data store, then it can help save storage costs to an extent. But the drawback of such stores is the SLA in retrieval since ‘Cold Storage’ is not accessible in real-time and only available on-demand. SLAs are usually in hours and vary with each cloud provider.
2. For redundant storage, one has to pay extra for redundancy.
Figure 6 shows how the Web application architecture will look at this stage.
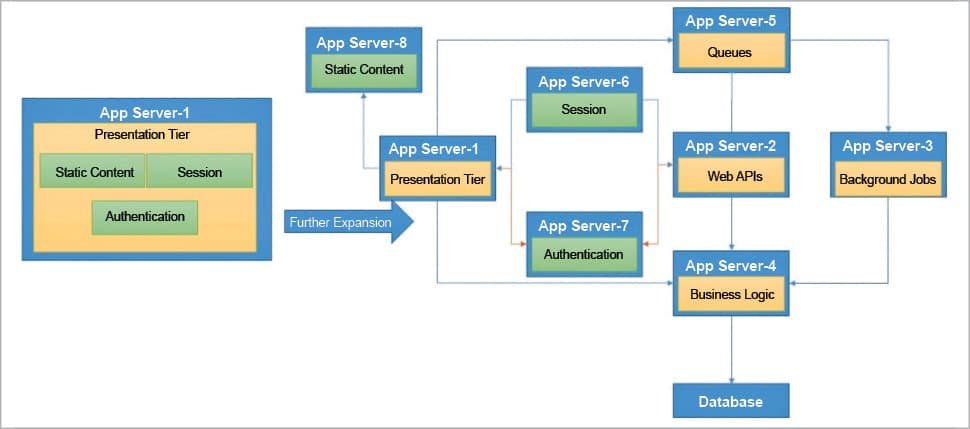
Practice #6: Divide the application tiers further to scale only the components that need to be scaled.
A multi-tiered approach will help application components to have dedicated resources and can be configured in low-end servers which can be scaled-out/in, on demand.
With the help of further tiers, we are able to achieve the highest level of elasticity from the deployment architecture standpoint. However, managing a plethora of servers could become a nightmare and scaling them independently is the worst part. But, thankfully, with the evolution of the cloud and the elastic nature of the infrastructure, one need not worry about managing scale-out/in (which is mostly automatic).
Practice #7: The background jobs function in a multi-threaded environment, so one must ensure jobs are completed on time even with huge amounts of data to be processed.
There may be certain use cases that one could come across like processing orders, sending emails, sending notifications, etc. These include processes that cannot be processed in real-time, or those that can be processed only at a certain time (like sending newsletters to customers). This occurs mostly in monolithic applications cases, in which case, services or daemons are created to run on top of databases, picking one job at a time and processing it.
One can scale such operations using queues, wherein the jobs to be processed get added to the queue, and one or ‘n’ worker processes can execute the jobs in parallel. One can achieve scalability by increasing or decreasing the number of worker processes. The most popular queues in the open source world are RabbitMQ, ZeroMQ, Apache ActiveMQ, Kafka and BeanStalkD (see Table 3 for a comparative analysis). All of these work with most major languages and one can easily find the client libraries for them. There are other options available when it comes to message broker mechanisms, like ActiveMQ, IronMQ, Apache Kestrel, Apache QPID, etc.
| Technology | Pros | Cons |
| RabbitMQ | ACK and NACK, re-queuing and delay/scheduled messaging support Data persistence is built-in |
Not easy to scale The central node adds latency if scaled |
| Kafka | Very high throughput Data persistence is default Supports online as well as offline processing |
Transaction support not available but can be implemented |
| ZeroMQ | Persistence is default Routing is easy Easily scalable |
No transaction support |
Scalability is an integral part of the software design process and the application must be designed such that the application components can be de-coupled and can scale independently. The concept of scaling will also require one to design applications to have no footprint on the application server so that there can be quick allocation/de-allocation of servers. There are patterns available in each technology to achieve such goals and it is a matter of how and when to implement it.














