























































The initial growth of data on the Internet was primarily driven by a greater population gaining access to the Web. This improved access was fuelled by the advent of a newer range of devices like smartphones and tablets. Riding on the first generation of data growth, a second wave of scaled up data production was unleashed mainly by the social media platforms that drove the growth upwards, exponentially. The collaborative nature of the information-sharing platforms contributed to a viral growth of the data shared via these platforms. The third wave of data generation is largely being led by the proliferation of intelligent connected devices and will lead to a scale of data generation that is unprecedented. In addition, the advancements in scientific fields coupled with the availability of cheaper computing has led to newer applications in the fields of medical sciences, physics, astronomy, genetics, etc, where large volumes of data are collected and processed to validate hypotheses, and enable discoveries and inventions.
The huge growth in data acquisition and storage has led us to the next logical phase, which is to process that data to make sense of it. The need to process this vast volume of data has led to the demand for scalable and parallel systems that process the data at speed and scale. Open source technologies are a natural choice for the high performance computing needed for large scale data processing.
This article aims to provide an overview of the frameworks and components available in open source, across different layers of a Big Data processing stack.
Component architecture stack for Big Data processing
As more and more Big Data, characterised by the three Vs – volume, velocity and variety – began to be generated and acquired, different systems started to evolve to tap the vast and diverse potential of this data. Although some of the systems converged in terms of the features they offered, they were all driven by different underlying design philosophies and, therefore, offered different alternatives. However, one of the guiding principles to develop enterprise data strategies would be to have a generic data storage layer as a data lake, which would allow different computing frameworks to work on the data stored for different processing use cases, and have the data shared across frameworks. Figure 1 illustrates a representational architectural stack for Big Data processing.
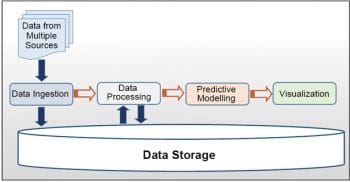
The stack can also be visualised as a pipeline consisting of multiple stages through which the data is driven, as can be seen in Figure 2. The unstructured and often schemaless raw data that is sourced from multiple sources, such as transactions, weblogs, open social sites, other linked data sources and databases, devices and instruments, could be in varying formats such as textual data, images, video, audio, etc. This data is then cleaned and often checked for any errors when ingested into the data storage layer. It is then processed, a task that might occur iteratively and interactively using the frameworks described in later sections. The processing could itself have multiple sub-stages and could revert data back into the storage layer at every iteration. It could be further explored and modelled using statistical algorithms to derive and validate hypotheses. These algorithms are trained on the data to learn the models, which can then be used for predictive modelling. The models could then be trained periodically as newer datasets flow into the system. The datasets are further used for exploratory analytics to discover unseen intelligence and insights. During the processing and exploratory processes, the processed datasets are visualised using visualisation tools to aid data understanding and for communicating to stakeholders.
This data in the storage layer could be reused by different stakeholders within an organisation. Big Data is typically undefined and most frameworks, as we will see later, have adapted to this aspect of it. In fact, this very feature is instrumental in the success of a framework.
Let us discuss some of the frameworks and libraries across these different layers.
The storage and data layer
Lets start with the storage and data layer, which is the most critical and the foundation of a Big Data stack. Big Data is typically characterised by its volume, requiring huge and conceptually unlimited storage capacities. Advances in technology, contributing to cheaper storage and compute resources, have resulted in the emergence of cluster storage and compute platforms. The platforms have unlocked the storage limitations and virtually enabled unlimited amounts of data storage. These platforms are not limited by the traditional paradigms of data modelling and schema designs. They are generally schema-free and allow the storage of all forms of data (structured, semi-structured and unstructured). This enables the creation of systems that are more dynamic and which enable analysts to explore the data without being limited by preconceived models. In this section, we will look at some of the popular cluster storage frameworks for Big Data.
HDFS (https://hadoop.apache.org/): This is a scalable, fault-tolerant distributed file system in the Hadoop ecosystem. HDFS is scaled by adding commodity servers into the clusters. The largest cluster size is known to be about 4500 nodes in a cluster with up to 128 petabytes of data. HDFS supports parallel reading and writing of data. The bandwidth in an HDFS system scales linearly with the number of nodes. There is built-in redundancy with multiple copies of data stored in the system. The files are broken into blocks and stored as files across the cluster. They are replicated for reliability.
HDFS has a master/slave architecture, wherein a cluster has a single component called NameNode, which acts as the master server. NameNode manages the file system namespace (files, directories and blocks, as well as their relationships). The namespace is stored in the memory and changes are persisted into the disk on a periodic basis.
In addition to that, there are slave components called DataNodes, usually one per node in the cluster. These processes manage the storage attached to the specific compute node they run on.
NoSQL databases (http://nosql-database.org/): As the Web has grown and become more accessible, it has become apparent that the existing relational database technologies are not equipped to handle the huge volumes and concurrency requirements of Web 2.0. To meet this need Not only SQL databases have emerged as alternate data storage and management systems. While HDFS and Hadoop are data processing engines for analytics use cases, either in batch or real-time, NoSQL databases essentially serve as data storage layers for Web based front-end systems that need large concurrent data handling capacities.
Some of the key features that characterise these databases are that they are usually schema-free (or have a minimal schema structure), horizontally scalable, and rely on eventual consistency models rather than immediate consistency models.
There are four basic architectures of NoSQL databases that have emerged. These are:
- KeyValue stores are based on the data model of hash data structures or associative arrays. These systems were based on Amazons DynamoDB paper (http://www.allthingsdistributed.com/files/amazon-dynamo-sosp2007.pdf).
- Columnar databases (DBs) are based on Googles BigTable paper (http://research.google.com/archive/bigtable-osdi06.pdf).The data model here is that each row can have its own schema, e.g., HBase and Cassandra.
- Document DBs are systems where the data is stored as documents, and each document is a collection of KeyValue pairs. Generally, these are expressed as JSON documents (e.g., MongoDB and CouchDB).
- Graph DBs are systems where the data models are represented as nodes, or as relationships between the nodes. Both nodes and relationships are represented in key-value pairs (e.g., Neo4J).
Tachyon (http://tachyon-project.org/): This is a platform that provides reliable in-memory data sharing across cluster frameworks and jobs. Tachyon essentially sits on top of storage platforms such as HDFS, thereby providing memory-centric data processing capabilities across cluster frameworks and jobs. Although some of the existing cluster computing frameworks like Spark, etc, have leveraged in-memory data processing, there were three key shortcomings that motivated the development of Tachyon:
- Although jobs processed data within memory, sharing of data across jobs and frameworks was not achieved as the data was only available within the JVM context of the job.
- As the execution engine and storage was within the same JVM context, any execution engine crash led to the loss of data and necessitated re-computation.
- Data was replicated in-memory across jobs in certain cases leading to a larger data footprint, and heavier garbage collection.
Tachyon was developed to solve the above problems and was driven by a need to push lineage down to the storage layer. It enables storing of only one copy of data in the memory, which is made available across all frameworks such as Spark, MapReduce, etc. Moreover, fault tolerance was enabled by leveraging re-computations using lineage.
Data processing frameworks
Once the data is persisted into a storage layer, the next step is to process this data to derive insights. There are several frameworks that we will look at here.
The Apache Hadoop stack (https://hadoop.apache.org/) is the grand-daddy of Big Data processing frameworks, and has become the de-facto platform into which the technology has largely converged. The cost-effectiveness and the scalability of the platform is a perfect match for the needs of the large scale data processing in the industry. In addition, the reliability and the community support around the platform and the ecosystem have led to a wider adoption of the platform.
The Hadoop ecosystem has three main goals:
Scalability – enabling scaling to cater to larger requirements with just the addition of nodes to the cluster. This is further amplified by the fact that the framework relies on the local computation model to derive benefits from the simplified scalability model.
Flexibility - to provide the flexibility to store differently structured data formats. This is enabled by the Schema on Read approach, which enables the system to store anything, and only decipher the schema at the time of reading the data, which is when it is required to know the data.
Efficiency - to ensure the cluster resources are optimally utilised for higher efficiency.
Hadoop MapReduce (https://hadoop.apache.org/) is the implementation of the MapReduce programming paradigm (popularised by a Google paper). This programming paradigm is modelled to process very large datasets in parallel, on large clusters, while ensuring reliability and fault-tolerance.
The MapReduce() paradigm itself is founded on the concept of a distributed file system which ensures reliability and scalability. A MapReduce() program consists of two procedures Map() and Reduce(). The Map() procedure processes the input dataset in parallel and emits a processed output. As the Map() phase happens across a very large distributed dataset, spread across a huge cluster of nodes, it is subsequently run through a Reduce() phase which aggregates the sorted dataset, coming in from multiple map nodes. This framework, along with the underlying HDFS system, enables processing of very large datasets running into Petabytes, spread across thousands of nodes.
Apache Flink (https://flink.apache.org/) is a data processing system that combines the scalability and power of the Hadoop HDFS layer along with the declarations and optimisations that are the cornerstone of relational database systems. Flink provides a runtime system, which is an alternative to the Hadoop MapReduce framework.
Apache Tez (https://tez.apache.org/) is a distributed data processing engine that sits on top of Yarn (Hadoop 2.0 ecosystem). Tez models the data processing workflows as Distributed Acyclic Graphs (DAGs). With this distinctive feature, Tez allows developers to intuitively model their complex data processing jobs as a pipeline of tasks, while leveraging the underlying resource management capabilities of the Hadoop 2.0 ecosystem.
Apache Spark (https://spark.apache.org/) is a distributed execution engine for Big Data processing that provides efficient abstractions to process large datasets in memory. While MapReduce on Yarn provides abstraction for using a clusters computational resources, it lacks efficiency for iterative algorithms and interactive data miningalgorithms that need to reuse data in between computations. Spark implements in-memory fault tolerant data abstractions in the form of RDDs (Resilient Distributed Datasets), which are parallel data structures stored in memory. RDDs provide fault-tolerance by tracking transformations (lineage) rather than changing actual data. In case a partition has to be recovered after loss, the transformations need to be applied on just that dataset. This is far more efficient than replicating datasets across nodes for fault tolerance, and this is supposedly 100x faster than Hadoop MR.
Spark also provides a unified framework for batch processing, stream data processing, interactive data mining and includes APIs in Java, Scala and Python. It provides an interactive shell for faster querying capabilities, libraries for machine learning (MLLib and GraphX), an API for graph data processing, SparkSQL (a declarative query language), and SparkStreaming (a streaming API for stream data processing).
SparkStreaming is a system for processing event streams in real-time. SparkStreaming treats streaming as processing of datasets in micro-batches. The incoming stream is divided into batches of configured number of seconds. These batches are fed into the underlying Spark system and are processed the same way as in the Spark batch programming paradigm. This makes it possible to achieve the very low latencies needed for stream processing, and at the same time integrate batch processing with real-time stream processing.
Apache Storm (https:/storm.apache.org/) is a system for processing continuous streams of data in real-time. It is highly scalable, fault tolerant, and ensures the notion of guaranteed processing so that no events are lost. While Hadoop provides the framework for batch processing of data, Storm does the same for streaming event data.
It provides Directed Acyclic Graph (DAG) processing for defining the data processing pipeline or topology using a notion of spouts (input data sources) and bolts. Streams are tuples that flow through these processing pipelines.
A Storm cluster consists of three components:
- Nimbus, which runs on the master node and is responsible for distribution of work amongst the worker processes.
- Supervisor daemons run on the worker nodes, listen to the tasks assigned, and manage the worker processes to start/stop them as needed, to get the work done.
- Zookeeper handles the co-ordination between Nimbus and Supervisors, and maintains the state for fault-tolerance.
Higher level languages for analytics and querying
As cluster programming frameworks evolved to solve the Big Data processing problems, another problem started to emerge as more and more real life use cases were attempted. Programming using these computing frameworks got increasingly complex, and became difficult to maintain. The skill scalability became another matter of concern, as there were a lot of people available with domain expertise familiar with skills such as SQL and scripting. As a result, higher level programming abstractions for the cluster computing frameworks began to emerge, that abstracted the low level programming APIs. Some of these frameworks are discussed in this section.
Hive (https:/hive.apache.org/) and Pig (https:/pig.apache.org/) are higher level language implementations for MapReduce. The language interface internally generates MapReduce programs from the queries written in the high level languages, thereby abstracting the underlying nitty-gritty of MapReduce and HDFS.
While Pig implements PigLatin, which is a procedural-like language interface, Hive provides the Hive Query Language (HQL), which is a declarative and SQL-like language interface.
Pig lends itself well to writing data processing pipelines for iterative processing scenarios. Hive, with a declarative SQL-like language, is more usable for ad hoc data querying, explorative analytics and BI.
BlinkDB (http:/blinkdb.org/) is a recent entrant into the Big Data processing ecosystem. It provides a platform for interactive query processing that supports approximate queries on Big Data. As data volumes have been growing exponentially, there has been an increasing amount of continuing research happening in this space to create computing models that reduce latency. Apache Spark was an effort in that direction, which worked on reducing latency using in-memory data structures.
Blink DB went further to squeeze the latency benchmarks by driving a notion of approximate queries. There were several industry use cases that appeared to tolerate some error in the answers, provided it was faster. BlinkDB does this by running queries against samples of original datasets rather than the entire datasets. The framework makes it possible to define the acceptable error bounds for queries, or specify a time constraint. The system processes the query based on these constraints and returns results within the given bounds.
BlinkDB leverages the notion of the statistical property sampling error which does not vary with the population size, but rather depends on the sample size. So the same sample size should hold reasonably well with increasing data sizes. This insight leads to an incredible improvement in performance. As the time taken in query processing is mostly I/O bound, the processing time can be increased by as much as 10x with a sample size of 10 per cent of the original data, with an error of less than 0.02 per cent.
BlinkDB is built on the Hive Query engine, and supports both Hadoop MR as well as Apache Shark execution engines. BlinkDB provides an interface that abstracts the complexities of approximation, and provides an SQL-like construct with support for standard aggregates, filters and groupBy, joins and nested queries, apart from user-defined functions with machine language primitives.
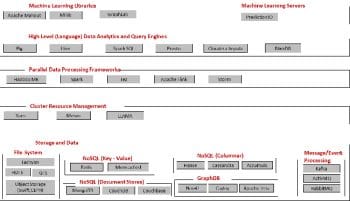
Cluster resource management frameworks
Cluster resource management is one of the key components in the Big Data processing stack. Successful frameworks that have emerged have been able to combine generality in supporting different frameworks with disparate processing requirements as well as the robustness to handle volume and recovery seamlessly. A generic framework will avoid the need to replicate massive amounts of data between different disparate frameworks within a cluster. It is also very important to provide interfaces at this layer that enable ease of administration and use. We will discuss a couple of frameworks that have shown promise at this layer.
Apache Hadoop Yarn (https://hadoop.apache.org/): Hadoop 1.0 was written solely as an engine for the MapReduce paradigm. As Hadoop became widely accepted as a platform for distributed Big Data batch processing systems, requirements grew for other computing patterns like message passing interfaces, graph processing, real-time stream processing, ad hoc and iterative processing, etc. MapReduce, as a programming pattern, did not support these kinds of requirements, and newer (as well as other existing) frameworks started to evolve. Also, HDFS was widely accepted for Big Data storage. It did not make sense to replicate data for other frameworks. The Hadoop community worked on re-hauling the platform to take it beyond MapReduce. The result of this was Hadoop 2.0, which separated resource management from application management. The resource management system was named Yarn.
Yarn is again a master-slave architecture, with the resource manager acting as a master that manages the resource assignments to the different applications on the cluster. The slave component is called the NodeManager, runs on every node in the cluster, and is responsible for launching the compute containers needed by the application.
The ApplicationMaster is the framework-specific entity. It is responsible for negotiating resources from the ResourceManager and working with the node manager to submit and monitor the application tasks.
This decoupling allowed other frameworks to work alongside MapReduce, accessing and sharing data on the same cluster, thereby helping to improve cluster utilisation.
Apache Mesos (http:/mesos.apache.org/) is a generic cluster resource management framework that can manage every resource in the data centre. Mesos differs from Yarn in the way the scheduling works. Mesos implements a two-level scheduling mechanism, where the master makes resource offers to the framework schedulers, and the frameworks decide whether to accept or decline them. This model enables Mesos to become very scalable and generic, and allows frameworks to meet specific goals such as data locality really well.
Mesos is a master/slave architecture with the Mesos master running on one of the nodes, and is shadowed by several standby masters that can takeover in case of a failure. The master manages the slave processes on the cluster nodes and the frameworks that run tasks on the nodes. The framework running on Mesos has two components: a scheduler that registers with the master, and the framework executor that launches on the Mesos slave nodes. In Mesos, the slave nodes report to the master about the available resources on offer. The Mesos master looks up the allocation policies and offers the resources to the framework as per the policy. The framework, based on its goal and the tasks that need to be run, accepts the offer completely, partially or can even decline it. It sends back a response with the acceptance and the tasks to be run, if any. The Mesos master forwards the tasks to the corresponding slaves, which allocate the offered resources to the executor, and the executor in turn launches the tasks.
Machine learning libraries
Big Data would not be worth the effort if it didnt provide a business value at the end. Machine learning programs the systems to learn or process large amounts of data, and be able to apply the learnings to predict outcomes on an unseen input dataset. Machine learning systems have enabled several real world use cases such as targeted ad campaigns, recommendation engines, next best offer/action scenarios, self-learning autonomous systems, etc. We will look at a few of the frameworks in this space.
Apache Mahout (http://mahout.apache.org/) aims to provide a scalable machine learning platform with the implementation of several algorithms out-of-the-box, and provides a framework for implementing custom algorithms as well. Although, Apache Mahout was one of the earliest ML libraries, it was originally written for the MapReduce programming paradigm. However, MapReduce was not very well suited for the iterative nature of machine learning algorithms and hence did not find great success. However, after Spark started gaining momentum, Mahout has been ported to Apache Spark, rebranded as Spark MLLib, and has been discontinued on Hadoop MapReduce.
Spark MLLib (https:/spark.apache.org/mllib/) is a scalable machine learning platform, which is written on top of Spark and is available as an extension of the Spark Core execution engine. Spark MLLib has an advantage as it has been implemented as a native extension to Spark Core. Spark MLLib has several algorithms written for ML problems such as classification, regression, collaborative filtering, clustering, decomposition, etc.
PredictionIO (http:/prediction.io/) is a scalable machine learning server that provides a framework enabling faster prototyping and productionising of machine learning applications. It is built on Apache Spark and leverages Spark MLLib to provide implementation templates of several machine learning algorithms. It provides an interface to expose the trained prediction model as a service through an event server based architecture. It also provides a means to persist the trained models in a distributed environment. The events generated are collected in real-time and can be used to retrain the model as a batch job. The client application can query the service over REST APIs and get the predicted results back in a JSON response.










