




























































The SaaS offering from Sastra Technologies, a firm that I co-founded, promises customers their very own database, which means that each customer has a separate database for its operational data. This puts a lot of pressure on our engineering team to ensure the database is provisioned and the SaaS widgets are up and running within minutes of the customers signing up. In the beginning, we were inclined to run a few shell scripts and have these set up by an engineer; however, we soon realised that our customers are based in the UK and could sign up while we were asleep. We had to enable this by automating the entire provisioning process. We initially looked at Puppet, Chef and FAI but these solutions had a pricing plan and, being a start-up, our aim was to conserve funds. So we decided to roll out our own provisioning scripts using the Digital Ocean API.
The case for automation
We had several compelling reasons for automating our provisioning. The primary reason was to guard ourselves against our inability to scale and provide infrastructure in case there was a flood of sign ups, especially in the middle of the night.
Automation would also ensure that subsequent environments would be identical to those set up previously this is important because we didnt want components to fail due to differences in the versions of the underlying infrastructure components.
The background
Digital Ocean (DO) is a cloud computing provider and is ranked 15th among hosting companies in terms of Web-facing computers, according to a news item in Netcraft and as of writing this article, has just announced a new region in London.
As a company, we host on several of its servers. The rest of this article is about our experience in automatically provisioning the DO infrastructure.
An overview of the Digital Ocean API (DO API)
The Digital Ocean API is a RESTful API, which means that users can access the functions using HTTP methods. The API allows you to manage the resources in a programmatic wayyou can create new droplets (instances), resize them, install additional packages and do a lot more.
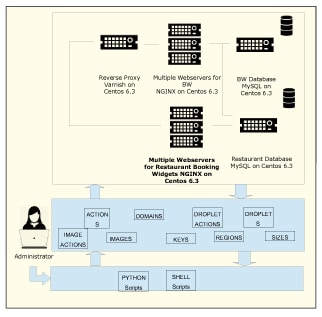
The solution diagram
Figure 1 gives a view of the various components that were included in the technology stack. Those highlighted are the ones that need to horizontally scale out and the rest of this article discusses how we accomplished this.
Rolling out the shell script using the DO API
To roll out your own scripts you will need to know UNIX shell programming, some Python and the Digital Ocean API reference. We chose to use Python because of its simple but powerful command set. You will also need to register and set up a
Digital Ocean account. Though not an absolute necessity, prior experience in setting up the infrastructure would help. So lets get started by creating our first Droplet programmatically.
Spinning a new Droplet
The first step in provisioning is to instantiate a virtual server, which Digital Ocean calls a Droplet; so lets first spin a Droplet. Fire up your editor, key in the following Python code and save it as DON-Droplet.py
def main(DropletName):SizeID = GetSizeID (2GB)OSID = Geomagnetic (CentOS 6.4 x32)RegID = GetRegID (Singapore 1)SshID = GetSSH(sridhar@sridhar-Aspire-5745)if (SizeID == ERROR or OSID == ERROR or RegID == ERROR or SshID == ERROR):print Size/OS/Region/Ssh ID Not Found. So Exiting...returnprint Size ID::[ + SizeID + ] OS ID::[ + OSID + ] Region ID::[ + RegID + ] SSH ID::[ + SshID + ]print Creation of Droplet::[...Startprint DropLet Name::[ + DropletName + ]CreateDroplet (DropletName, SizeID, OSID, RegID, SshID)print Creation of Droplet...Endreturn |
The main function allows us to specify the size of the Droplet (yes, for now we have hardcoded it!), the image ID of the OS that you want to install, the ID of the region in which you want to create your Droplet and the SSH keys that you want to install. Each of these values is passed to the respective functions to check if they are valid before we create the Droplet with those values. For example, to check if the size we have specified is valid and available, we use the following function:
def GetSizeID (SizeName):RespArr = GetDON (sizes)if RespArr == ERROR:print Problem in getting sizes from DON.return ERRORfor RespRow in RespArr:RespRow = Clean (RespRow)#print arr entries->, RespRowFlds = dict (Fld.split (:) for Fld in RespRow.split (,))if Flds[name] == SizeName:print Size::[ + SizeName + ] id::[ + Flds[id] + ]. Foundreturn Flds[id].strip()print Size::[ + SizeName + ] Not Found.return ERROR |
We query the API with GetDON (sizes) to get the list of the available sizes. The API returns an array with the list of available sizes and we parse the array to check if we have the size thats specified by the user in the main function. If we have the required size, the rest of the checks like Image ID and Region ID are performed by the respective functions: GetImageID (CentOS 6.4 x32), GetRegID (Singapore 1), and GetSSH (sridhar@sridhar-Aspire-5745). If any of these checks fail, we abort Droplet creation. If the checks are successful, we proceed to create the Droplet using CreateDroplet (DropletName, SizeID, OSID, RegID, SshID).
The Python function to create a Droplet takes the name, size, OS Image ID, Region ID and the SSH key as arguments, and uses the RESTful API to create the Droplet. A word of caution: the API keys provided here are dummy keys, just for illustrating the flow of the code. You will have to obtain your keys by registering with Digital Ocean.
def CreateDroplet (Name, Size, OS, Reg, Passkey):#Copying DONs Parameters..data = {}data[client_id] = xj53GXMazSf3NCCznoLdata[api_key] = 941c3d1a0240e900ae450848c94data[name] = Namedata[size_id] = Sizedata[image_id] = OSdata[region_id] = Regdata[ssh_key_ids] = PasskeyURL_Values = urllib.urlencode(data)#Connect to DON for values of APIKey...URL = https://api.digitalocean.com/droplets/new?Full_URL = URL + URL_Valuesprint Droplet Creation URL->[ + Full_URL + ].print Connecting DON to create dropletprint URL Execution Start...data = urllib2.urlopen(Full_URL)DON_Result = data.read()print Droplet Creation Response::[ + DON_Result + ]print URL Execution End.return |
Thats all it takes to create a Droplet. Since we used an SSH key, the root password will not be emailed to us. Log in to the new Droplet using SSH and youll be prompted for the password since we havent yet disabled the password authentication in sshd_conf configuration. So youll have to go to the Web console and request for your password or you should not use the SSH keys while creating the Droplet!
Lets now create the users we require and install our infrastructure componentsMySQL, PHP, NGINX, Munin, APC, Memcached and Postfix.
Setting up a Droplet
Before installing the components, first set up the time zone, create users, add them to a group and set up the firewall rules. In our case, we set up the time zone to IST, created users, added them to WHEEL (so that they have super cow powers), and then closed all ports except those we required. You can create this as a shell script called droplet-admin.bash or download it from www.opensourcefoyu.com/articles/article_source_code/nov14/cloud_inventory.zip. Run the script to make the above changes or you can do it one by one.
Deploying the cloud stack
Let us now write a script to install PHP Fast CGI, MySQL, Nginx, APC, memcached and Munin.
Lets start with the script for installing the PHP-fCGI. Choose fCGI instead of the conventional PHP module as the former is known to have a lower memory footprint. Create a php-install.bash file with the following contents:
yum install php php-fpm -yrpm -ivh http://dl.fedoraproject.org/pub/epel/6/x86_64/epel-release-6-8.noarch.rpmyum install php-mcrypt -yyum install php-gd php-imap -yecho cgi.fix_pathinfo=0 >> /etc/php.iniecho date.timezone = America >> /etc/php.iniservice php-fpm startservice php-fpm status |
This script installs php php-fpm. It then downloads the php-mcrypt, php-gd, php-impa from the epel repositories and installs them. Php-fpm requires the cgi.fix_pathinfo=0 to be set in the php.ini file, which is done by the echo command. The script then automatically starts php-fpm.
After PHP, the next thing to be installed is MySQL. Create mysql-install.bash by using the following commands:
yum install mysql mysql-server -ychkconfig --levels 235 mysqld onservice mysqld startservice mysqld status |
The script installs MySQL and configures it to start up automatically when the server starts up. The script currently doesnt remove the demo database. You might want to include that step.
NGINX is not available from the official Centos repositories and the official package has to be downloaded from the NGINX site. Create nginx-install.bash with the following lines. This will enable the appropriate repositories and install NGINX:
wget http://nginx.org/packages/rhel/6/noarch/RPMS/nginx-release-rhel-6-0.el6.ngx.noarch.rpmrpm -ivh nginx-release-rhel-6-0.el6.ngx.noarch.rpmyum install nginx -ychkconfig nginx onservice nginx startservice nginx status |
Our next step is to install APC or the Alternate PHP Cache, which is available in PECL. Create apc-install.bash with the following lines. This will install APC.
yum install php-pear php-devel httpd-devel pcre-devel gcc make -ypecl install apcecho extension=apc.so > /etc/php.d/apc.ini |
Next, we need to install memcached. Just create memcached-install.bash with the following command:
yum install memcached -y |
Any technology stack requires to be monitored, for which we use munin. To install munin, create munin-install.bash with the following commands:
yum --enablerepo=epel install munin munin-node -y/etc/init.d/munin-node startchkconfig munin-node onservice munin-node status |
We now have the individual scripts to install the various components of our stack. We can create a master script infra-install.py to chain these individual shell scripts. You can download infra-install.py from www.opensourcefoyu.com/articles/article_source_code/nov14/cloud_inventory.zip
To provision your Droplet and have it ready, all you need to do is to run infra-install.py (ensure all your scripts have the requisite permissions for executing it).
Other methods
The other method of provisioning hosting infrastructure is to use one of the several products available like Puppet, Chef, CFEngine, Cobbler, FAI, Kickstart, BCFG2 or Vagrant.
Scope for improvement
For the sake of brevity, we have included the essential commands to get you started on auto-scaling your infrastructure. But there are a few things that you should include to improve these scripts.
Currently, we have to log in once before we execute the other commands because though we have provided SSH keys for the root user at the time of creating the Droplet, we havent disabled password authentication in the sshd_config file.
Though we create users, the script doesnt automatically copy the public keys for the users. You can add a few commands to automatically copy the SSH keys to the respective HOME directories and disable the password authentication mechanism.
After installing MySQL, it is a good practice to remove the test databases and anonymous users. The script currently doesnt do this.
You can add AWStats to the list of infrastructure components.
You might want to run this suite of scripts as a Jenkins Job instead of manually running it.
References
[1] https://developers.digitalocean.com/ provides a detailed guide for developers to navigate the API calls.











