


Git is a powerful distributed version control system that is free and open source. It was created by Linus Torvalds in 2005 when the Linux project had to move away from BitKeeper. Since then, there has been constant addition of functionality and improvement in performance. Today, it is recognised as one of the fastest distributed version control systems. As a result, in the past few years, many open source projects have migrated to Git from SVN, CVS and other version control systems.
However, the power of Git also means that it can be incorrectly used, resulting in confusing revision history after merges and consequent difficulties in tracking code changes. At worst, it could result in loss of code as well. Also, many developers with a background in centralised version control find it difficult to understand the distributed nature of Git and how to use it effectively. This has created a mental barrier, where project teams hesitate to use Git, due to its perceived difficulty and uncertainty in workflow.
There are many books that describe how to use Git and also cover its internals. But these get into complex details, and do not provide a template workflow that can be used by project teams that are embarking on new development but are new to Git.
Installation and initial configuration
Git is packaged by most Linux distributions. So you can use apt, yum or any other package management system provided by your distribution to install Git.
However, in case the version provided by your distribution is older and you would like to install the latest version, you can obtain the source from https://git-scm.com/. This may be the only option in case you do not have administrator access to install packages, yet want to install Git in your home directory.
Once done, you need to fill in information about yourself in Git so that it can be used in the commits made by you. This step is mandatory for every developer. So proceed as follows:
$ git config --global user.name Your Name$ git config --global user.email your.name@yourcompany.com |
Support tools
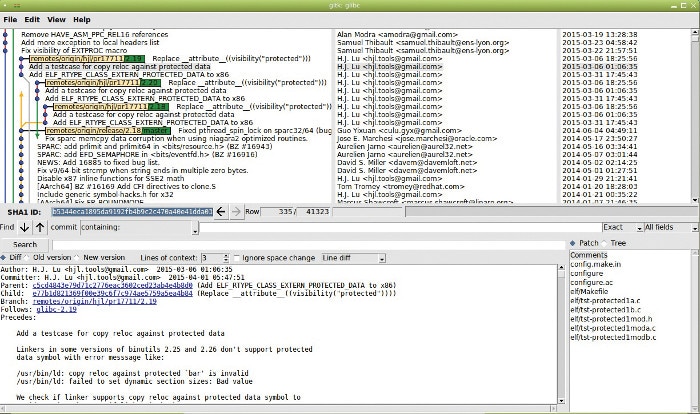
Along with Git, it is useful to install a graphical tool that displays the history of a Git repository. This tool is called gitk. If this is not already on your system, it can be installed via the gitk package.
A sample output of the tool is shown in Figure 1.
For bash users, another useful addition is to have Git auto-completion added to your bash shell. This helps you type Git commands faster on the bash command line, by pressing the tab after typing the first few characters of the Git command. The Git auto-completion bash script can be downloaded from https://github.com/git/git/blob/master/contrib/completion/git-completion.bash
You can then add the same into your .bashrc. For example, the following code can be added to ~/.bashrc:
source ~/.git-completion.bash |
In addition, the PS1 prompt can be modified to show the branch that you are in, when inside a Git repository. The .bashrc can modify the PS1 prompt as follows:
PS1=[\u: \w$(__git_ps1 (%s))]$ |
This results in an output as shown in Figure 2.
This is very handy when you are working on multiple branches. A common error that developers make, i.e., committing code to the wrong branch, can be avoided with this simple step.
Official repository
In Git, all repositories are complete and equal. All developers own their repository. Hence, the official repository just refers to the Git repository identified by the project as official’ and usually owned by maintainer, who is identified by the project team.
All developers clone their individual repositories from this official repository. Note that the maintainers themselves may have a cloned repository where they do the development work.
All official builds (release builds, nightly builds, etc) need to be made out of the official repository. Therefore, all code needs to be brought into the official repository ultimately. Thus, code can be considered as committed to the project only after it reaches this official repository from the individual developers repository.
Cloning the official repository
The official repository can be cloned as follows:
$ git clone ssh://userid@ip-addr/path-to-repo [<dir-name>] |
<dir-name> is optional. If omitted, the same name as in the official repository is created. The Git repository which is cloned is called origin.
Branches
Every Git repository has a master branch. The master branch of a clone is not the same as the master branch of the origin. But the master branch of a cloned repository tracks the master branch of origin. It is called a tracking branch.
Cloning automatically creates the master branch in the cloned repository. Other branches can be created using the following command:
$ git branch <branch-name> |
The branch is local to the repository where it is created. The local branch can be pushed to origin.
To move to a specific branch, use the following command:
$ git checkout <branch-name> |
Rules relating to tracking branches
As mentioned above, the master branch of a cloned Git repository is a tracking branch. You can track any other branch in the origin Git repository using the
following command:
$ git checkout <remote-branch-name> |
This creates a local branch with the same name as the remote branch, and which tracks the latter.
Now, here are some rules to be adhered to when working on tracking branches:
- Never work directly on any tracking branch
- Create a development branch off a tracking branch for changes that need to go into that tracking branch
- Use $ git pull –all in each tracking branch periodically, to keep it in sync with the origin repository
You can use the tracking branch as a reference to post code changes for review. For example, if the popular review-board (https://www.reviewboard.org/) code review tool is being used by your project team, you could use the following command:
$ post-review tracking-branch=<tracking-branch-name> |
…to post reviews for changes in that development branch.
The Git workflow
When working on a feature or a defect, it is best to adhere to the steps provided below as your development workflow. The purpose of these steps is to have a single commit addressing a single issue, which is consistent and complete in itself, while also having a clean merge history in the official repository.
At this point, we will assume that your repository reflects the latest state of the official repository. If you have a repository cloned a while ago, pull the latest changes pushed to the official repository, using the following command:
$ git pull -all |
Step 1: Create a branch where you will modify code for the feature/defect assigned to you. Create the branch from the master branch, or from a release branch, to where the code must ultimately go.
Use the branch only for the specific feature or defect. Do not mix code changes for different work items in the same branch.
Step 2: Modify the code and test it.
Step 3: Commit it to the working branch.
Step 4: Send the code for review using the code review tool that your project uses, for example, review-board.
Step 5: Rework the code based on review feedback, re-test it and resend for further review. Steps 2 to 5 are repeated until review approval is obtained.
Step 6: Once review approval is received, update the master branch and rebase the working branch to get the development repository in sync with the latest code. While code changes are merged automatically most of the time, sometimes manual code merges may need to be done.
Step 7: Squash multiple commits (say, due to review feedback) into a single commit. Based on experience, I can say this is seldom done by developers. But, this is important to ensure that the Git version history looks clean and there is a single diff for a single unit of code change. This also makes it easy to cherry-pick a change into another branch.
Step 8: Send the patch to the maintainer of the official repository to incorporate your changes into the main repository.
First, ensure you are in the master branch. Now, you can create a branch to make the code changes. Say you are fixing bug-ID 1234. Then, the <branch-name> below can be bug1234.
Note: We will use the master branch as an example here, though it could be any other branch in the official repository where you want the code changes to go.
The few specific commands that can be used for each of the above steps are detailed. Comments are shown below in C-style syntax. These are for clarity only and not to be typed.
$ git branch <branch-name> /* Create branch */$ git checkout <branch-name> /* Move to branch *//* Modify code *//* Build & test */$ git add <files> /* Stage file for commit */$ git commit /* Give meaningful commit log *//* Send for review */ |
After review approval, update the master and rebase your branch. Rebasing is an essential step, which ensures that any changes made by other developers and pushed to the official repository (after your cloning) are visible in your branch. Any merge conflicts can be resolved by you, facilitating a clean merge by the maintainer.
$ git checkout master /* Move to master branch */$ git pull --all /* Sync with latest code in origins master branch */$ git checkout <branch-name> /* Move back to working branch */$ git rebase master /* Sync branch with latest code *//* Fix merge conflicts, if any, and re-test */ |
Now, squash multiple commits into a single commit via interactive rebase.
$ git rebase i HEAD~<#> |
In the above command, <#> is the number of commits from HEAD to squash; for example:
$ git rebase i HEAD~3 |
Pick only the required commit and squash other commits with the one picked.
The changes can now be submitted to the maintainer for incorporation into the official repository.
$ git format-patch origin (or) $ git format-patch -1 |
The above command will generate files of the type 0001-xxxxx.patch. If the commit squash was done, only one file will be generated. Send these files to the maintainer via email.
What maintainers normally expect is that the mail containing a patch to be incorporated in the official repository should also mention the branch to which the patch is to be applied, the bug-ID, and the proof of review approval (such as the review URL). The maintainer will usually send a confirmation once the patch is applied.
You can now pull changes from the main repository into your master branch and delete the working branch, using the following code:
$ git checkout master$ git pull all/* Verify submitted changes are present in master */$ git branch d <branch-name> |
Working on multiple work items
Normally, a developer works on multiple work items. For example, the developer may be assigned a feature and multiple bugs. Having a separate cloned repository for each work item is ideal. But due to disk quota, this is a luxury for most developers. Instead, they need to work on the same cloned repository. This is facilitated by Git, which provides a way to stash work and come back to it later.
As mentioned earlier, each work item must be on a separate branch. So, we can save uncommitted code before switching branches by stashing the changes, as shown below:
$ git stash save <message>$ git checkout <other-branch>
$ git checkout <earlier-branch>$ git stash pop -index |
You may stash changes in multiple branches. To view the stashed changes, use the following code:
$ git stash list |
To apply a specific stash once you are back in a branch, use the command shown below:
$ git stash apply <stash-name> --index$ git stash drop <stash-name> |
Note that git stash drop is used to remove a stashed set of changes after it is applied via git stash apply. Git does not remove it automatically, on the assumption that you may need it later for some other branch. This behaviour is unlike that of git stash pop, which removes the stashed changes that were popped out.
Labelling
Any project would want to label code at specific milestones. Git allows us to label any specific code snapshot. Apply a label with a comment, using the following code:
$ git tag a <label> -m <info on label> |
To get to a labelled code snapshot, use the following command:
$ git checkout <label> |
Release management
Release management deals with creating a release version of your project for external consumption. Project members label the code snapshot used to create the release version. This helps the project team to go back to the specific code snapshot at any time in the future, often to resolve issues reported in the released product.
The release is usually done from the official repository, where you need to go through the sequence of steps that follow:
- Apply a label with ver# as per project conventions, e.g., myproject_release_v1.0
- Also, create a branch with ver# as per project conventions, e.g., myproject_release_1.0_branch
- There are some rules when it comes to release branches in the official repository:
- Release branches must never be deleted.
- Release branches must not be rebased with the master or any other branch.Release branches are long-lived branches, unlike development (working) branches described earlier.
- Label any hot-fix releases done out of the release branch as per project conventions.
Cherry-picking
When defects are reported in a released version, there could be a need to fix code in a release branch and issue updates.
The recommended workflow for handling issues in a release branch is as follows:
Step 1: Check if a defect exists in the master branch, and if so, fix it in the master branch.
Step 2: Cherry-pick the commit into the concerned release branch by using the following code:
/* Do bug fix and commit to master */$ git checkout <release-branch>$ git cherry-pick -m master <commit-id>/* Test again in release version to make sure *//* Push to official-repository */ |
Note that since we had squashed multiple commits into a single logical commit for the defect concerned, as part of our development workflow, only a single commit needed to be cherry-picked. If squash was not done, we would have had to track and cherry-pick multiple commits.
Common errors while using Git and how to recover from them
There are times when we make mistakes, but the power of Git helps us to recover from them. However, for the following actions, do read up the documentation and understand what they do and what the side-effects could be, before use.
- To undo a wrong change in a file which is not committed, use the command given below:
$ git checkout -- <file> |
- If you missed committing a file from a commit that you just made, issue the following command:
$ git add <missed-file>$ git commit amend |
- If you wrongly committed some change, use the command shown below:
$ git reset HEAD~1 |
- If you messed up and want to go to a clean slate without having to clone again (i.e., you dont want generated or untracked files around), use the following code:
$ git clean -xfd |
References
[1] Git Magic: http://www-cs-students.stanford.edu/~blynn/gitmagic/
[2] Pro Git: http://git-scm.com/book
[3] Online reference: http://git-scm.com/docs
Book: Version Control with Git, Jon Loeliger and Matthew McCullough, OReilly Publishers.


