




























































As per international statistical reports, every day, WhatsApp gets around 1 million new user registrations and has 700 million active users. Around 30 billion messages get sent and 34 billion messages are received daily (source: statista.com). Twitter statistics reveal 350 million tweets daily and more than 500 million accounts. Data is growing at a rapid rate every moment, and there are predictions that the production and generation of data in 2020 will be 44 times more than 2009 levels (source: http://wikibon.org/blog/big-data-statistics/).
This data is unstructured in nature, which means that it is in different and heterogeneous formats. Such vast volumes are typically known as Big Data. Deep investigation of intelligent and meaningful patterns from such data is known as Big Data analytics. A number of researchers and scientists are working in this domain using assorted technologies and tools. There are a number of ways in which live data can be obtained for research and development. One of these is getting data from open data portals. These portals provide authentic data sets for research and development in multiple domains, which can be downloaded in multiple formats including XML, CSV, JSON and many others.
Prominent portals for fetching open data
- Datahub is available at https://datahub.io/
- Book-Crossing – http://www.informatik.unifreiburg.de/~cziegler/BX/
- World Health Organization – http://www.who.int/research/en/
- The World Bank – http://data.worldbank.org/
- NASA – https://data.nasa.gov/
- United States Government – http://www.data.gov/
- Machine Learning – http://bitly.com/bundles/bigmlcom/2
- Scientific Data University of Muenster – http://data.uni-muenster.de/
- Hilary Mason research-quality – https://bitly.com/bundles/hmason/1
The other way to get data sets is to generate our own data sets using programming languages. The major issue here is the selection of a suitable programming language or tool that can fetch live data from social media applications or live streaming portals. The usual programming languages are not effective in fetching live streaming data from the Internet.
Python is one of the outstanding and efficient programming languages that can communicate with the live streaming servers. You can use it to store the fetched data in the database or file system for analysis and predictions.
Lets move on to look at some real-life cases in which Python has been used to fetch live streaming data.
Web scraping using Python scripts
Python scripts can be used to fetch live data from the Sensex. This technique is known as Web scraping.
Figure 1 gives a screenshot of the live stock market index from timesofindia.com. The frequently changing Sensex is fetched using Python and stored in a separate file so that the record of every moment can be saved. To implement this, the library of BeautifulSoup is integrated with Python.
The following code can be used and executed on Python. After execution, a new file named bseindex.out will be created and second-by-second Sensex data will be stored in it. Once we flood the live data in a file, this data can be easily analysed using data mining algorithms with SciLab, WEKA, R, TANAGRA or any other data mining tool.
from bs4 import BeautifulSoupimport urllib.requestfrom time import sleepfrom datetime import datetimedef getnews():url = http://timesofindia.indiatimes.com/businessreq = urllib.request.urlopen(url)page = req.read()scraping = BeautifulSoup(page)price = scraping.findAll(span,attrs={class:red14px})[0].textreturn pricewith open(bseindex.out,w) as f:for x in range(2,100):sNow = datetime.now().strftime(%I:%M:%S%p)f.write({0}, {1} \n .format(sNow, getnews()))sleep(1) |
Using a similar approach, YouTube likes can be fetched and analysed using Python code, as follows:
from bs4 import BeautifulSoupimport urllib.requestfrom time import sleepfrom datetime import datetimedef getnews():url = https://www.youtube.com/watch?v=VdafjyFK3ko req = urllib.request.urlopen(url)page = req.read()scraping = BeautifulSoup(page)price = scraping.findAll(div,attrs={class:watch-view-count})[0].textreturn pricewith open(baahubali.out,w) as f:for x in range(2,100):sNow = datetime.now().strftime(%I:%M:%S%p)f.write({0}, {1} \n .format(sNow, getnews()))sleep(1) |
Fetching all the hyperlinks of a website
All the hyperlinks of a website can be fetched by using the following code:
from bs4 import BeautifulSoupimport requestsnewurl = input ("Input URL")record = requests.get("http://" +newurl)mydata = record.textmysoup = BeautifulSoup(mydata)for link in mysoup.find_all('a'):print(link.get('href')) |
Using Python in cloud infrastructure
There are a number of service providers offering private or public cloud services. Listed below are a few prominent cloud and Big Data based service providers that provide options to code and deploy one’s own applications:
- Amazon EC2
- IBM Bluemix
- Microsoft Azure
- Qubole
Cloud service providers make use of specialised packages and tools for coding in different languages. Python can be used on these cloud computing infrastructures.
On IBM Bluemix, the cloud services can be accessed using https://console.ng.bluemix.net/, and can be used once the credentials are verified. Cloud infrastructure can be used with the Cloud Foundry CLI (Command Line Interface).
After installation of Cloud Foundry (CF), one can communicate with the remote server. To check the version, the following command is used:
$ cf -v |
The following instruction is used for pushing the application on the cloud server:
$ cf push MyApp -m 128M -b https://github.com/cloudfoundry/cf-buildpack-python.git |
Programming Python for NoSQL databases
NoSQL databases are being used in social media applications and portals that process Big Datain which huge, heterogeneous and unstructured data formats are handled. NoSQL databases are used for faster access of records from the big data set at the back-end. The Aadhaar card implementation in India is being done using NoSQL databases as huge amounts of information are involved, including text data, images, thumb impressions and iris detection. No traditional database system can handle data sets of different types (text, video, images, audio, thumb impressions, iris samples, etc) simultaneously.
Currently, a number of NoSQL databases are used for different types of portals, and these specialise in handling heterogeneous and unstructured data.
In traditional Web based implementations, RDBMS packages are deployed for database applications including Apache Derby, MySQL, Oracle, IBM DB2, Microsoft SQL Server, IBM Notes, PostgreSQL, SQLite, Sybase, etc. These are known as traditional SQL databases that comply with the ACID (atomicity, consistency, isolation and durability) properties. NewSQL is the new-generation database engine that provides the scalability and performance of NoSQL systems for online transaction processing (OLTP) read-write workloads, while maintaining the ACID guarantees of a classical database system.
Nowadays, Web applications use unstructured data in heterogeneous formats including audio, video, text, streaming, signals, images, pixels and many others. In each file pattern, there are a number of file formats. For instance, in video, there are a number of file formats including MPEG, MP4, AVI, 3GP, WMV, OGG, FLV and others. In the same manner, image or graphics file formats include GIF, PNG, JPEG, PCX, BMP, TIFF and lots of others.
The major issue here is the compatibility of Web applications with all these file formats in different domains. Heres where the concept of NoSQL databases comes into play since they enable any type of file format to be processed and integrated in the Web applications. A NoSQL (Not Only SQL) database provides the system for storing and retrieving data, and is not modelled on the tabular relations methodology used in relational databases. The data structure in NoSQL databases is entirely different from that in traditional RDBMSs. Currently, the former are being rapidly adopted in Big Data and real-time Web applications.
There have been various approaches to classifying NoSQL databases, each with different categories and sub-categories. Because of the variety of approaches and overlaps it is difficult to get an overview of non-relational databases. A few categories are listed below:
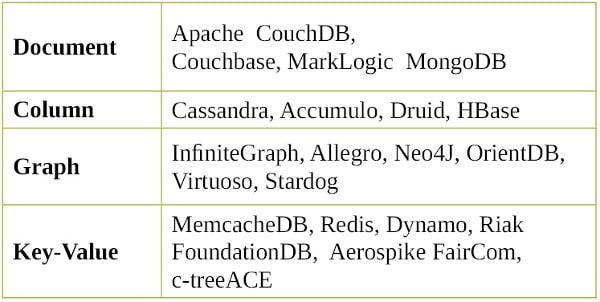
Programming Python – CouchDB
Apache CouchDB is one of the most popular open source databases, widely used as a document-oriented NoSQL database. Like most other NoSQL databases, CouchDB uses the JSON (JavaScript Object Notation) format to store data. The JSON format is the open standard data file format that is used as an alternate to XML to transmit data between multiple incompatible and heterogeneous servers.
The following example shows a sample JSON representation:
{FirstName: X,LastName: X,LiveStatus: X,Gender: X,},ContactDetails: [{ContactType1: X,Number: X},{ContactType2: X,Number: X}],JobStatus: [X],PAN: X} |
Installing CouchDB
On Ubuntu and Debian Linux systems, use the following command:
$ sudo ptitude install couchdb |
For Gentoo Linux, use the command below:
$ sudo emerge couchdb |
The services can be started or stopped using the init scripts in all the distributions as follows:
$ /etc/init.d/couchdb start |
The CouchDB installer is available for Windows from http://couchdb.apache.org. The CouchDB installed on the system can be executed in standalone mode as well as in service mode.
Futon: A GUI administrator panel for CouchDB
Futon is the Web based GUI panel that is built for CouchDB. It provides the basic interface for a majority of the functions including creating, deleting, updating and viewing documents. It provides access to the configuration parameters and an interface for initiating replication (see Figures 3 and 4).
CouchDBs interaction with Python
To interface Python with CouchDB, a specialised package called couchdb is used with the following main modules:
- couchdb.client: This is a client library for interfacing with CouchDB
- couchdb.mapping: This module provides the advanced mapping between JSON documents of CouchDB and Python objects
- couchdb.view: This module implements the view based server for the views written in Python
>>> import couchdb>>> couch = couchdb.Server() |
The above code creates the server object. The default URL is localhost:5894.
On live servers, the code will be as follows:
>>> couch = couchdb.Server(http://www.mybigcloudportal.com:5984/)>>> mydb = couch.create(testDB) |
The above code creates a new database.
>>> mydb = couch[mynosqldb] |
The above code is to use the existing database.
>>> mydoc = {Country: India} |
After selecting a database, the above code is used to create a document and insert it into the database.
>>> mydb.save(mydoc) |
The save() method shown above returns ID and the revfor the currently created document.
>>> mydb.delete(doc)>>> couch.delete(testDB) |
The above command is for cleaning the document and database.
Using CouchDBKit
The goal of CouchDBKit is to provide a dedicated framework for the Python application to manage and access CouchDB.
The following features are inherent with CouchDBKit:
- To use the http backend using py-restclient
- Managing documents dynamically
- Threadsafe
- Attaching design docs with the application and sending these to CouchDB
- Managing documents with a dynamic schema
In order to install CouchDBKit using Pip, use the following commands:
$ curl -O http://python-distribute.org/distribute_setup.py$ sudo python distribute_setup.py$ easy_install pip |
For installation or upgrading to the latest released version of CouchDBKit, use the command given below:
$ pip install couchdbkit |
The following is the code you can use to work with CouchDBKit:
from couchdbkit import Servermyserver = Server()db = myserver.create_db(couchbdkit_test)db[myid] = { x: Hello }doc = db[myid] |
You can map a CouchDB object to a Python object easily with a dynamic schema, as follows:
from couchdbkit import Documentclass MyDBClass(Document):author = StringProperty()content = StringProperty()date = DateTimeProperty()MyDBClass = MyDBClass()MyDBClass.author = AuthorNameMyDBClass.homepage = http://couchdbkit.org |
Once this is done, the first CouchDB document will be as shown below:
import datetimefrom couchdbkit import *class MyDBClass(Document):author = StringProperty()content = StringProperty()date = DateTimeProperty() |
Here is the code to save a MyDBClass on the MyDBClass database. We also see how to create a database.
server = Server()db = server.get_or_create_db(MyDBClass)MyDBClass.set_db(db)MyDBClass = MyDBClass(author=AuthorName,content=Welcome,date=datetime.datetime.utcnow()) MyDBClass.save() |
Programming Python – MongoDB
First, MongoDB and PyMongo are installed so that the connection of Python with MongoDB can be established. In the Python shell, the following instruction is executed:
$ import pymongo |
Next, the MongoClient is created by running the mongod instance. The following code is connected on the default host and port:
>>> from pymongo import MongoClient>>> myclient = MongoClient() |
The specific host and port can be mentioned explicitly as follows:
>>> myclient = MongoClient(localhost, 27017) |
Alternatively, the MongoDB URI format can be used as shown below:
>>> myclient = MongoClient(mongodb://localhost:27017) |
The MongoDB instance is able to support multiple and independent databases, which can be obtained with the use of attribute style access on MongoClient instances, as follows:
>>> mydb = myclient.MyTestDatabase |
Similarly, other instructions of Python for MongoDB can be used for unstructured and Big Data processing.











