

Introducing AWK, a programming language designed for text processing and typically used as a data extraction and reporting tool. This language is a standard feature of most UNIX-like operating systems.
AWK, one of the most prominent text-processing utilities on GNU/Linux, takes its name from the initials of its authors — Aho, Weinberger and Kernighan. It is an extremely versatile programming language that looks a little like C. It is a scripting language that processes data files, especially text files that are organised in rows and columns.
AWK really is a consistent tool with a few data types. Its portability and stability have made it very popular. It’s a concise scripting language that can tackle a vast array of problems. It can teach the reader how to implement a database, a parser, an interpreter and a compiler for a small project-specific computer language.
If you are already aware of regex (regular expressions), it’s quite easy to pick up the basics of AWK. This article will be useful for software developers, systems administrators, or any enthusiastic reader inclined to learn how to do text processing and data extraction in UNIX-like environments. Of course, one could use Perl or Python, but AWK makes it so much simpler with a concise single line command. Also, learning AWK is pretty low cost. You can learn the basics in less than an hour, so it doesn’t require as much effort and time as learning any other programming/scripting language.
The original version of AWK was written in 1977 at AT&T Bell Laboratories. In 1985, a new version made the programming language more powerful, introducing user-defined functions, multiple input streams and computed regular expressions.
-
AWK’s first version came out in 1977 (old AWK)
-
NAWK – this was an extended version that was released in 1985 (new AWK)
-
MAWK – an extended version by Michael Brennan
-
GAWK – GNU-AWK, which is faster and provides better error messages
Typical applications of AWK include generating reports, validating data, creating small databases, etc. AWK is very powerful and uses a simple programming language. It can solve complex text processing tasks with a few lines of code. Starting with an overview of AWK, its environment, and workflow, this article proceeds to explain its syntax, variables, operators, arrays, loops and functions.
AWK installation
Generally, AWK is available by default on most GNU/Linux distributions. We can use the which command to check whether it is present on your system or not. In case you don’t have AWK, then install it on Debian based GNU/Linux using the Advanced Package Tool (APT) package manager, as follows:
sudo apt-get install gawk
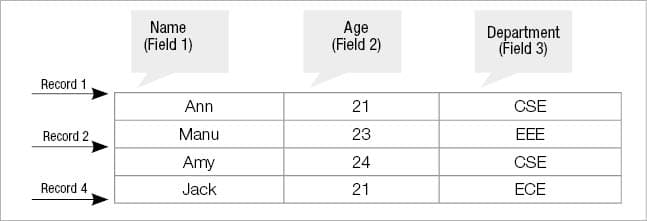
AWK is used for stream processing, where the basic unit is the string. It considers a text file as a collection of fields and records. Each row is a record, and a record is a collection of fields.
The syntax of AWK is as follows.
On the command line:
awk [options] ‘pattern {action}’ input file
As an AWK script:
awk [options] script_name input file
The most commonly used command-line options of awk are -F and -f :
-F : to change input field separator -f : to name script file
A basic AWK program consists of patterns and actions — if the pattern is missing, the action is applied to all lines, or else, if the action is missing, the matched line is printed. There are two types of buffers used in AWK – the record buffer and field buffer. The latter is denoted as $1, $2… $n, where ‘n’ indicates the field number in the input file, i.e., $ followed by the field number (so $2 indicates the second field). The record buffer is denoted as $0, which indicates the whole record.
For example, to print the first field in a file, use the following command:
awk ‘{print $1}’ filename
To print the third and first field in a file, use the command given below:
awk ‘{print $3, $1}’ filename
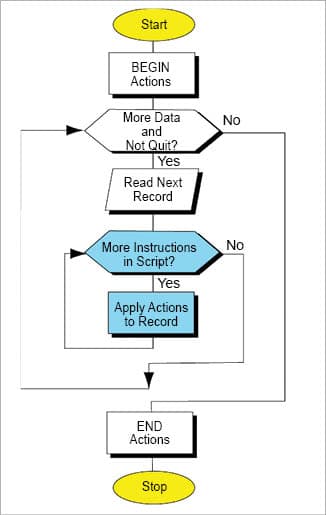
AWK process flow
So how does one write an AWK script?
AWK scripts are divided into the following three parts — BEGIN (pre-processing), body (processing) and END (post-processing).
| BEGIN {begins actions} |
| Patterns{Actions} |
| END {ends actions} |
BEGIN is the part of the AWK script where variables can be initialised and report headings can be created. The processing body contains the data that needs to be processed, like a loop. END or the post-processing part analyses or prints the data that has been processed.
Let’s look at an example for finding the total marks and averages of a set of students.
The AWK script is named as awscript.
#Begin Processing
BEGIN {print “To find the total marks & average”}
{
#body processing
tot=$2+$3+$4
avg=tot/3
print “Total of “ $1 “:”, tot
print “Average of “$1 “:”, avg
}
#End processing
END{print “---Script Finished---”}
Input file is named as awkfile
Input file (awkfile)
Aby 20 21 25
Amy 22 23 20
Running the awk script as :
awk –f awscript awkfile
Output
To find the total marks & average
Total of Aby is : 66
Average of Aby is : 22
Total of Amy is : 65
Average of Amy is : 21.66
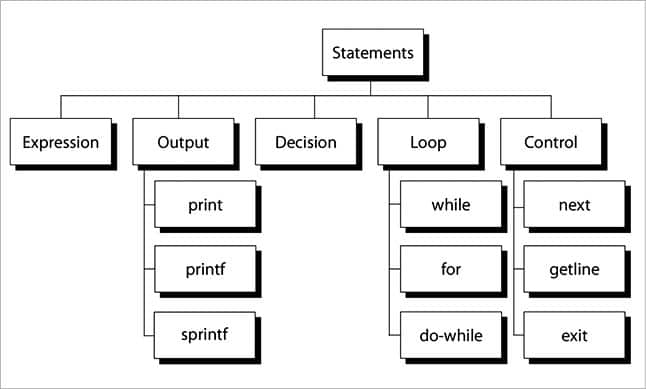
Classification of patterns
Expressions: AWK requires two operators while writing regular expressions (regex) — match (~) and doesn’t match (!~). Regular expressions must be enclosed in /slashes/, as follows:
awk ‘$0 ~ /^[a-d]/’ file1 (Identify all lines in a file that starts with a,b,c or d) awk ‘$0 !~ /^[a-d]/’ file1 (Identify all lines in a file that do not start with a,b,c or d)
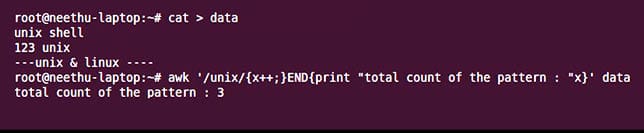
An example of an expression is counting the number of occurrences of the pattern ‘unix’ in the input file ‘data’.
Awk supports the following:
Arithmetic operators: + , – , * , /, % , ^ .
Relational operators: >, >=, < ,<=, ==, != and…
Logical operators: &&, ||, !.
As an example, consider the file awktest:
1 unix 10 50
2 shell 20 10
3 unix 30 30
4 linux 20 20
• Identify the records with second field, “unix” and value of third field > 40
awk ‘$2 == “unix” && $3 > 40 {print}’ awktest
1 unix 10 50
• Identify the records where, product of third & fourth field is greater than 500
awk ‘$3 * $4 > 500 {print}’ awktest
3 unix 30 30
Hence, no address pattern is entered, and AWK applies action to all the lines in the input file.
The system variables used by AWK are listed below.
FS: Field separator (default=whitespace)
RS: Record separator (default=\n)
NF: Number of fields in the current record
NR: Number of the current record
OFS: Output field separator (default=space)
ORS: Output record separator (default=\n)
FILENAME: Current file name
There are more than 12 system variables used by AWK. We can define variables (user-defined) also while creating an AWK script.
• awk '{OFS="-";print $1 , $2}' marks
john-85
andrea-89
• awk '{print NR, $1, $3}' marks
1 john cse
2 andrea ece
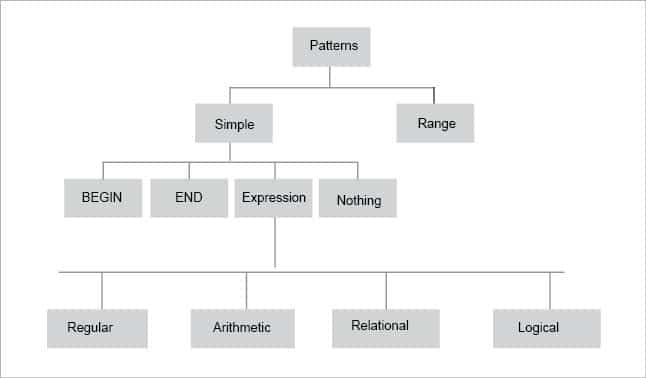
Range patterns: These are associated with a range of records, which match a range of consecutive input lines:
Start-pattern, end-pattern{actions}
Range starts with the record that matches the start pattern and ends with the record that matches the end pattern.
Here is an example:
Print 3rd line to 5th line, along with line numbers of the file, marks
• awk ‘NR==3, NR==5 {print NR, $0}’ marks
<strong> Action statements</strong><strong><a href="https://www.opensourceforu.com/wp-content/uploads/2017/07/Figure-4-Regular-Expression-in-awk.jpg"> </a>Expression statements:</strong> An expression is evaluated and returns a value, which is either true or false. It consists of any combination of numeric and string constants, variables, operators, functions, and regular expressions.
Here is an example:
{$3 = “Hello”}
{sum += ($2+4)}
Output statements: There are three output actions in AWK: print, printf and sprint.
- print writes the specified data to the standard output file.awk ‘{print $1, $2, $3}’ file name prints first, second and third columns.
- printf uses a format specifier in a ‘format-string’ that requires arguments of a matching type.
- string printf (sprintf) stores the formatted print string as a string.
str = sprintf(“%2d %-12s %9.2f”, $1, $2, $3)
As an example, consider the file, ‘data’:
12 abcd 12.2
13 mnop 11.1
• awk ‘{printf(“%@d %-3s %0.3f”, $1, $2, $3)}’ data
the above command appends an @ before first field, left assign second field, print third field with 3 decimal places
o/p
@12abcd 12.200
@13mnop 11.100
Decision statements: An if-else decision statement evaluates an expression and takes proper action. Nested if statements are also applied.
As an example, to print all records with more than three fields, type:
BEGIN{}
{
If(NF > 3)
print $0
else
print “Less than 3 fields”
}
To print the marks and grades of a student, type:
BEGIN{print “Mark & grade of a student”}
{
If($2==”Amy”)
S=S+$3
}
END{print “Total marks: “S
if(S>50)
print “Grade A”
else
print “Grade B”
}
Loop statements: While, do.. while and for are the loop statements in AWK. The AWK while loop checks the condition first, and if the condition is true, it executes the list of actions. This process repeats until the condition becomes false.
Here is an example:
BEGIN {print “Display even numbers from 10 to 20” }
{ #initialization
I = 10
#loop limit test
while (I <=20)
{ #action
print I
I+=2 #update
}
} # end script
do.. while loop
The AWK do while loop executes the body once, then repeats the body as long as the condition is true. Here is an example that displays numbers from 1 to 5:
awk ‘BEGIN {I=1; do {print i; i++ } while(i < 5)} ‘
Here is an example of the for loop:
program name : awkfor
BEGIN { print “ Sum of fields in all lines”}
{
for ( i=1; i<=NF; i++)
{
t=t+$i //sum of $1 + sum of $2
}
END { print “Sum is “ t}
Consider the input file : data
10 30
10 20
Running the script : awk –f awkfor data
Sum of fields in all lines
Sum is 70
Control statements: next, getline and exit are the control statements in AWK. The ‘next’ statement alters the flow of the program — it stops the current processing of pattern space. The program reads the next line and starts executing commands with the new line.
Getline is similar to next, but continues executing the script.
The exit statement causes AWK to immediately stop processing the input, and any remaining lines are ignored.
Mathematical functions in AWK
The various mathematical functions in AWK are:
int(x) — truncates the floating point to the integer
cos(x) — returns the cosine of x
exp(x) — returns e^x
log(x) — returns the natural logarithm of x
sin(x) — returns the sine of x
sqrt(x) — returns the square root of x
Here is an example:
{
x = 5.3241
y = int(x)
printf “truncated value is “, y
}
Output: truncated value is 5
String functions in AWK
1. length(string): Calculates the length of a string.
2. index(string, substring): Returns the first position of the substring within a string. For example, in x= index(“programming”, “gra”), x returns the value 4.
3. substr(): Extracts the substring from a string. The two different ways to use it are: substr(string, position) and substr(string, position, length).
Here is an example:
{
x = substr(“methodology”,3)
y = substr(“methodology”,5,4)
print “substring starts at “ x
print “ substring of length “ y
}
The output of the above code is:
Substring starts at hodology Substring of length dolo
4. sub(regex, replacement string, input string) or gsub(regex, replacement string, input string)
sub(/Ben/,” Ann “, $0): Replaces Ben with Ann
(first occurrence only).
gsub(/is/,” was “, $0): Replaces all occurrences
of ‘is’ with ‘was’.
5. match(string, regex)
{
x=match($0,/^[0-9]/) #find all lines that start with digit
if(x>0) #x returns a value > 0 if there’s a match
print $0
}
6. toupper() and tolower(): This is used for convenient conversions of case, as follows:
{
print toupper($0) #converts entire file to uppercase
}
User defined functions in AWK
AWK allows us to define our own functions, which enables reusability of the code. A large program can be divided into functions, and each one can be written/tested independently.
The syntax is:
Function Function_name (parameter list)
{
Function body
}
The following example finds the largest of two numbers. The program’s name is awfunct.
{
print large($1,$2)
}
function large(m,n)
{
return m>n ? m : n
}
Input file is: doc
100 400
Running the script: awk –f awfunct doc
400
Associative arrays
AWK allows one-dimensional arrays, and their size and elements need not be declared. An array index can be a number or a string.
The syntax is:
arrayName[index] = value
Index entry is associated with an array element, so AWK arrays are known as associative arrays.
For example, dept[$2] indicates an element in the second column of the file and is stored in the array, dept.
Program name : awkarray
BEGIN{print “Eg of arrays in awk”}
{
dept[$2]
for (x in dept)
{
print a[x]
}
}
Consider the input file, data
S3 CSE A
S4 ECE B
S4 EEE A
Running the script : awk –f awkarray data
Eg of arrays in awk
CSE
ECE
EEE
AWK is oriented towards delimited fields on a per-line basis. It has very robust programming constructs including decision statements like if..else, and loops like while and do.. while.
We can conclude by saying that AWK is another keystone of UNIX shell programming. It really shines when it comes to simplifying things like processing multiline records and interpolating multiple files simultaneously. AWK inherits the features of conventional programming languages.
So not only was AWK popular when it was introduced but it has also led to the creation of other popular languages.
More details about this text processing utility can be found in the books: ‘The AWK Programming Language by Alfred V. Aho, Brian W. Kernighan, and Peter J. Weinberger (1988-01-01); and ‘UNIX and Shell Programming’ by Behrouz A. Forouzan and Richard F. Gilberg, (Cengage Learning).


