



























































In laymen’s terms, computer architecture refers to how a computer is designed and how software interacts with it. With the demands on computing power increasing, it is a natural corollary that computer architecture should also evolve. This article highlights the challenges and opportunities in designing heterogeneous systems.
The emergence of mobility, social networking, campus networking and edge computing has brought with it an essential need to process varieties of data – within and outside of enterprise data centres. Traditional computing needs to cope not only with large volumes of data, but also with the wide variety and velocity of data. The need to handle data velocity, variety and volume exists across the entire computing landscape, starting from handheld devices to supercomputing infrastructure.
Purpose-built computers that are armed with FPGAs (field-programmable gate arrays) or accelerators and off-loading, assist in meeting some of the special data processing needs of today, such as scene detection from a remote camera feed, image search, and speech recognition. Faced with humongous Big Data processing needs—be it text, images, audio, video or data from billions of sensors—traditional computing architectures find it difficult to handle the volume, velocity and variety of the data. While it is true that over-provisioned general-purpose computing infrastructure or expensive specialised infrastructure can get the job done somehow, traditional computing infrastructure has shown itself to be inefficient in meeting the needs of Big Data. For efficient Big Data computing at the right cost, a paradigm shift is needed in computer architecture.
In today’s computing landscape, there are certain basic technology drivers that have reached their limits. Shrinking transistors have powered 50 years of advances in computing, as Moore’s Law, named after Intel co-founder Gordon Moore says “number of transistors in a dense integrated circuit doubles approximately every two years.” But for some time now, making transistors smaller has not made them more energy-efficient. So while the benefits of making things smaller have been decreasing, the costs have been rising. This is in large part because the components are approaching a fundamental limit of smallness—the atom.
On the other hand, disruptive technology trends like non-volatile memory and photonic interconnects call for revamping the existing, traditional architectures. There has also been a move by certain parts of the industry to adopt a data-centric computing paradigm, as opposed to the traditional CPU or compute-centric approach, though this nascent shift has largely remained at the level of academic research.
At the same time, there is a constant demand for improved performance to enable compelling new user experiences. New use cases like molecular modelling, photo-realistic ray tracing and modelling, seismic analysis, augmented reality and life sciences computing have really questioned how effective these traditional compute units are, in today’s context. To address the twilight of Moore’s Law and to navigate this complex set of requirements, the computer industry needs an approach that promises to deliver improvements across four vectors—power, performance, programmability and portability. This has led to the industry exploring the area of heterogeneous systems in order to meet the demands of newer compute- and data-centric applications.
In this article, we discuss the evolution of heterogeneous systems, as well as the challenges and opportunities in this field, with regard to compute units, interconnects, software architecture, etc.
Given the vastness and depth of this topic, we intend to provide a brief overview of heterogeneous systems in this issue, followed by a detailed in-depth discussion of their components over the following months in a series of subsequent articles. Understanding the changing landscape of heterogeneous systems would benefit those interested in next-generation disruptive computer architecture changes, as this brings in rich opportunities in the open source hardware and software ecosystem. Towards that, let us start by looking at how the computer architecture landscape has evolved over the years,
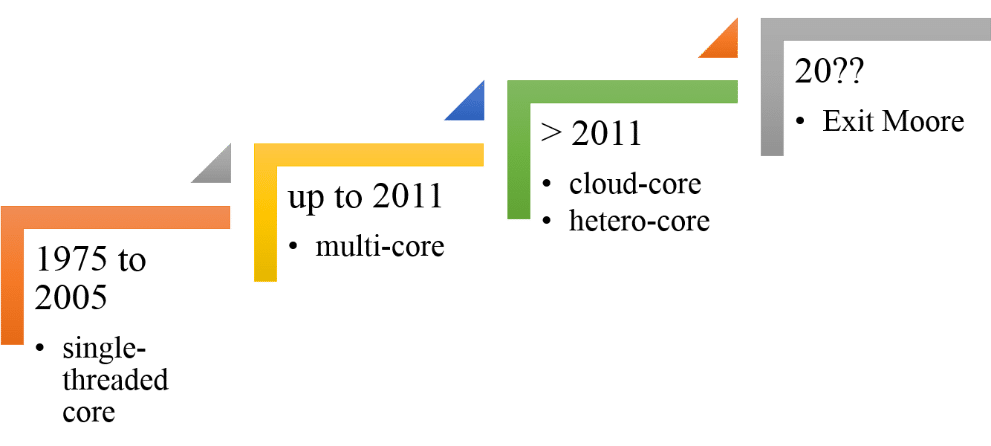
The evolution of computer architecture started out with computers that had single cores, before reaching today’s level of heterogeneous multi-core scale-out systems. As shown in Figure 1, from 1975 to 2005, the industry accomplished something phenomenal— getting PCs on desks, in millions of homes, and in virtually every pocket. The year 2005 saw a shift to computers with multi-core architecture, where parallel computing became a possibility to cater to the ongoing demand from users for better performance. It was in 2011 that we saw these parallel supercomputers with multi-cores coming out in popular form factors like tablets and smartphones.
The multi-core era
Multi-core systems can provide high energy efficiency since they allow the clock frequency and supply voltage to be reduced together to dramatically reduce power dissipation during periods when the full rate of computation is not needed.
A multi-core CPU combines multiple independent execution units into one processor chip, in order to execute multiple instructions in a truly parallel fashion. The cores of a multi-core processor are sometimes also denoted as processing elements or computational engines. According to Flynn’s taxonomy, the resulting systems are true multiple-instruction multiple-data (MIMD) machines, able to process multiple threads of execution at the same time.
The multi-core era saw two classes of systems — homogeneous multi-core systems (SMPs) and heterogeneous multi-core systems (HMPs).
Homogeneous multi-core systems
A symmetric multi-processor system (SMP) has a centralised shared memory called the main memory (MM) operating under a single operating system with two or more processors of the same kind. It is a tightly coupled multi-processor system with a pool of homogeneous processors running independently. Each processor executes different programs and works on different data, with the ability to share resources (memory, I/O devices, interrupt systems, etc) with interconnection using a bus/crossbar.

Heterogeneous multi-core systems
Heterogeneous (or asymmetric) cores promise further performance and efficiency gains, especially in processing multimedia, recognition and networking applications. For example, a big.LITTLE core includes a high-performance core (called ‘big’) and a low-power core (called ‘LITTLE’). There is also a trend towards improving energy-efficiency by focusing on performance-per-watt with advanced fine-grained power management, dynamic voltage and frequency scaling (i.e., in laptops and portable media players).
Software impact
Parallel programming techniques can benefit from multiple cores directly. Some existing parallel programming models such as CilkPlus, OpenMP, OpenHMPP, FastFlow, Skandium, MPI, and Erlang can be used on multi-core platforms. Intel introduced a new abstraction for C++ parallelism called TBB. Other research efforts include the Codeplay Sieve System, Cray’s Chapel, Sun’s Fortress, and IBM’s X10.
Limitations
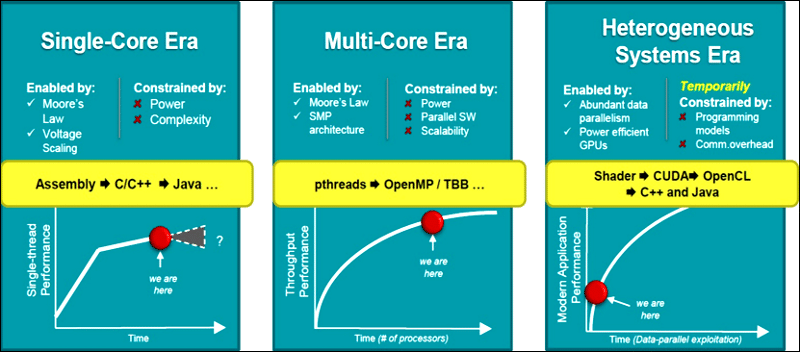
Having said that, multi-core systems do have limitations in terms of speed gained and effective use of available multiple cores (refer to Figure 2). As software developers, we will be expected to enable a single application to exploit an enormous number of cores that are increasingly diverse (being specialised for different tasks) and at multiple locations (from local to very remote; either on-die, in-box, on-premises or in-cloud). The increasing heterogeneity will continue to spur a deep and fast evolution of mainstream software development. We can attempt to predict some of the changes that could occur.
Amdahl’s Law
The original idea presented by Gene Amdahl is a general observation about the performance improvement limits of any enhancement, and was later summarised as the well-known Amdahl’s Law. When we apply Amdahl’s Law to parallel processing, we have the speedup metric as:
= Performancenew = SequentialExecutionTime = Ts
S Amdahl ______________ _______________________
Performanceold ParallelExecutionTime Tp
Let’s suppose that α is the fraction of the code that is sequential, which cannot be parallelised, and p is the number of processors. Assuming that all overheads are ignored, we have:
S Amdahl = T s = Ts = 1
___________________ _____________
T p αTs + (1 – α)Ts/p α + (1 - α)/p
This formula is called Amdahl’s Law for parallel processing. When p, the number of processors, increases to infinity, the speed-up becomes limp→∞ S Amdahl = lim p→∞ 1/ (α+ (1−α)/p) = 1/α. This equation shows that the speed-up is limited by the sequential fraction, a nature of the problem under study, even when the number of processors is scaled to infinity. Amdahl’s Law advocates that large-scale parallel processing is less interesting because the speed-up has an upper boundary of 1/α.
GPGPU
As the multi-core era was evolving, some adventurous programmers were exploring ways to leverage other compute units like the GPU (graphics processing unit) for general purpose computing. The concept of the GPGPU (general purpose graphic processing units) evolved at NVIDIA, AMD and other organisations. This involved offloading some pieces of code so that it runs on the GPU in parallel and boosts performance significantly. With the multi-core (scale-up model) era hitting a dead end, heterogeneous system architecture did show a ray of hope (scale-out model) by getting all the various compute units like the GPU, DSPs, ASSPs and FPGA together to address the current day’s needs.
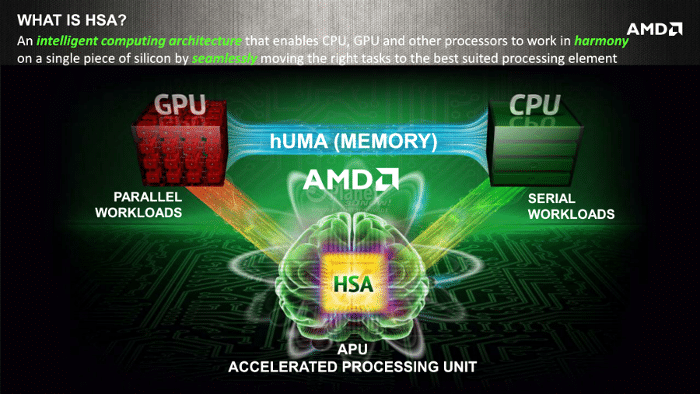
Heterogeneous systems
Heterogeneous system architecture integrates heterogeneous processing elements into a coherent processing environment enabling power-efficient performance. It is designed to enable extremely flexible, efficient processing for specific workloads and increased portability of code across processors and platforms. Figure 4 shows a hardware vendor’s perspective.
There are a wide range of applications that need heterogeneous high performance computing (HPC), such as astrophysics, atmospheric and ocean modelling, bio-informatics, bio-molecular simulation, protein folding, computational chemistry, computational fluid dynamics, computational physics, computer vision and image understanding, data mining and data-intensive computing, global climate modelling and forecasting, material sciences and quantum chemistry. Figure 5 provides an overview of AMD’s heterogeneous system architecture, called HSA.
So what does a heterogeneous system comprise? Dissecting such a system reveals varying types of computing units, interconnects, memory and software entities. The different types of compute units are the CPU, GPU, ASIC, DSP, ASSPs, FPGAs and SoCs. Various interconnects such as fabric connectivity, InfiniBand, RapidIO, PCIe, Ethernet and Omni-path are used to connect all these compute units. The memory hierarchies of each of the compute units access these memories in a unified manner. The software entities are largely impacted to support HSA, including the operating system, virtual machine (ISA), runtime libraries and the compiler tool chain.
Heterogeneous systems pose a unique challenge in computing as they contain distinct sets of compute units with their very own architecture. Since the instruction set architecture of each of the compute units is different, it becomes difficult to achieve load balancing between them. Each compute unit views the memory spaces disjointedly and hence consistency and coherency semantics are a challenge. Memory bandwidth and data transfer between each of the compute units can be a challenge too. Each of these units has its own programming models.
A CPU-centric execution model requires all functions to be delegated by the CPU even if intended for an accelerator. It is executed through the operating system and existing software layers. This leads to challenges such as overheads in scheduling parallel tasks on these units, maintenance of data dependencies (which requires programmers to account for and maintain the status of memory contents when switching between different compute units such as CPUs and GPUs), workload partitioning (choosing an appropriate compute unit for a given workload), and reaching higher levels of energy efficiency and power saving.
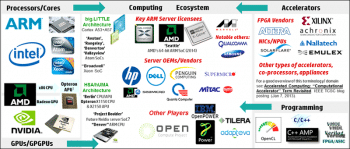
Heterogeneous systems are still evolving and various developments are happening in areas like the operating system, virtual machine (ISA), tool chain and runtime libraries. Open source compilers and tools like GCC and LLVM are supporting the polyhedral model for heterogeneous architectures. There is a separate community driving polyhedral compilation research. Figure 6 provides an overview of the ecosystem influencing the evolution of HSA.
NVIDIA’s CUDA alone could not cater to the evolving aspects of heterogeneous systems. Newer open platforms, standards, architectures like HSA Foundation, OpenCL, OpenACC, IBM’s Liquid Metal, and OpenHPC have emerged to provide the software stack for heterogeneous systems. Various open source projects are being run as part of the HSA Foundation, which one can leverage and contribute back to.
A distributed computing platform like Apache Spark and others have contributed a lot to the evolution of heterogeneous systems. As a result, platforms like SparkCL and HeteroSpark have evolved, which combine the scale-out power of distributed computing and the scale-up power of heterogeneous computing to create a very powerful HPC platform. Efforts are on to use the advancements made in NVM (non-volatile memory) technology in heterogeneous systems. OpenARC (Open Accelerator Research Compiler) is one such effort.
In short, it is clear that the mainstream hardware is becoming permanently parallel, heterogeneous and distributed. These changes are here to stay, and will disrupt the way we have to write performance-intensive code on mainstream architecture. This evolution of heterogeneous architecture clearly highlights the increasing demand for compute-efficient architectures. There are various proprietary heterogeneous architectures that address today’s challenges in their own way. The increasing demand for such architectures shows that the heterogeneous system architecture is inevitable and is the way forward. We will discuss the components of heterogeneous system architectures in depth in the forthcoming articles in this series.















