


























































There are only a handful of classical languages in the world. Which of them is the greatest in the world? This is one question I can answer without any difficulty. Its Sanskrit, the language considered by many as created by the Gods themselvesa language that preserves the collective wisdom of our great sages since time immemorial. It is absolutely impossible to fully comprehend the hidden pearls of wisdom in many of the ancient Sanskrit texts. Consider the Sanskrit sloka ’gopi bhagya madhuvrata srngiso dadhi sandhiga khala jivita khatava gala hala rasandara’. This sloka tells us about Lord Krishna, the eternal lover and his unmatched love for his gopikas. But hidden inside this sloka is the value of Pi up to 32 decimal places a feat that was achieved by European mathematicians centuries later. A technique called Katapayadi Sankhya, where letters in the Sanskrit alphabet are given numeric values, is used to hide numbers of great importance in seemingly unrelated Sanskrit slokas.
The above example shows that Sanskrit texts are full of ancient wisdom. But what does Sanskrit have to do with the open source initiative? This is an area where ancient wisdom meets modern wisdom. In this article, I am going to discuss a few areas in the open source arena that work in tandem with Sanskrit. The topics I have covered in this article are not comprehensive. I am only discussing those open source projects that caught my eye during my research. But I do believe it is absolutely essential to have a comprehensive list of open source projects dealing with Sanskrit.
Online Sanskrit dictionaries
My search for Sanskrit related open source projects started with online Sanskrit dictionaries. When I Googled the phrase online Sanskrit dictionaries I found many Sanskrit dictionaries with free content. But the result on the top, which was quite surprising, was http://spokensanskrit.de/. Google always returns results in the decreasing order of relevance. So this website is highly relevant according to Google. The domain extension .de is for Deutschland or Germany. So the best online Sanskrit dictionary is maintained by the Germans!
I have gone through the contents of the website it not only contains Sanskrit words but contains Sanskrit phrases also. I found out that it is not just a dictionary, but also helps you with Sanskrit to English translation and vice versa, which makes it a very useful tool. The dictionary even accepts Unicode based Sanskrit letters as input for searching the content. Moreover, it is an editable dictionary to which any registered user can contribute.
Sanskrit fonts and the open source initiative
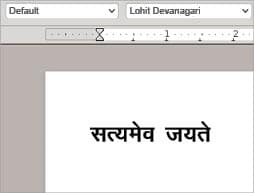
There are a lot of open source word processing packages like OpenOffice Writer and LibreOffice Writer. But how many of these packages support Sanskrit fonts? Well, I came across many Sanskrit fonts which can be used in these word processing packages. Two such fonts that caught my attention were Lohit Devanagari and Kruti Dev. Lohit Devanagari is the default font. Kruti Dev is a more recently developed font. Both these fonts can be used with LibreOffice Writer and produce good quality Sanskrit text. Currently, around forty variants of the Kruti Dev font are available, including variants like bold, italics, thin, wide, etc. Figure 1 shows the famous mantra ‘Satyameva Jayate‘ (truth alone triumphs) from the Mundaka Upanishad written in LibreOffice Writer with the Lohit Devanagari font.

LaTeX and Sanskrit
LaTeX is a word processor and a document markup language. Word processing packages like LibreOffice Writer use a page containing formatted text, whereas LaTeX uses a page containing plain text along with markup tags specifying the effects to be produced on the plain text. A LaTeX document has a .tex extension and on processing with a LaTeX engine will produce a PDF or DVI document as the output.
It is possible to typeset Sanskrit text using LaTeX. But standard keyboards do not have the Devanagari alphabet in them. So we need a transliteration scheme for translating text written in the English alphabet to Devanagari. Unlike usual LaTeX documents with an extension .tex, if your document contains the Devanagari script, then the extension is usually .dn. This file is then pre-processed with a macro to produce the corresponding .tex file. This .tex file is further processed by a LaTeX engine to produce the PDF or DVI output file.
So, unlike processing documents containing English letters, if you are processing Devanagari script, you need to use a two-step process. The C program called devnag.c to pre-process LaTeX files containing Devanagari script can be downloaded from the Comprehensive TeX Archive Network (CTAN) at www.ctan.org/tex-archive/language/devanagari/velthuis/. The file contains 2562 lines of excellent code one of the best I have ever come across. Again, to my surprise, I found out that the program was written by Frans J. Velthuis, a Dutchman associated with the University of Groningen in Netherlands! You just need to compile the C program to produce an executable, and then with this executable you need to pre-process the .dn file to produce the .tex file. The code below illustrates the compilation and execution of the C program devnag.c for pre-processing sanskrit.dn to produce sanskrit.tex:
[root@deepu Sanskrit]# gcc devnag.c -o devnag [root@deepu Sanskrit]# ./devnag sanskrit.dn
The transliteration scheme for Devanagari is clearly explained in the user manual available with the C file devnag.c. But obtaining just a .tex file is not our aim. We need to process the file sanskrit.tex further to obtain the PDF or DVI output file. For this you need to install a package called Devanagari. The style sheet for this package, called Devanagari.sty, is also available along with the other resources in the CTAN link mentioned earlier. The code below shows the file sanskrit.dn before its processed with the pre-processor program. If you observe the code carefully, you will see that whatever text comes inside the \dn environment is treated as Sanskrit by default.
\documentclass[12pt]{article}
\usepackage{devanagari}
\begin{document}
{\dn
\begin{center}
\Huge\framebox[6cm]{.o gurave nama.h}
\end{center}
}
\end{document}
The pre-processor program will take care of the transliteration scheme of the Devanagari characters. After processing, the file sanskrit.dn will yield a file called sanskrit.tex. The code below shows the file sanskrit.tex:
\def\DevnagVersion{2.15}\documentclass[12pt]{article}
\usepackage{devanagari}
\begin{document}
{\dn
\begin{center}
\Huge\framebox[6cm]{: \7{g}rv\? nm,}
\end{center}
}
\end{document}
The file sanskrit.tex is further processed by the LaTeX engine to produce the PDF or DVI output file. Figure 2 shows the PDF file sanskrit.pdf produced by the file sanskrit.tex and processed with pdfLaTeX. You can download all these files from https://www.opensourceforu.com/article_source_code/march2016/os_sanskrit.zip.
As mentioned earlier, by default, the package Devanagari will process text in Sanskrit mode. But if you need to write Hindi text using the package, you must use the command @hindi so that the pre-processor will assume you are working with Hindi characters.

Bharat Operating System Solutions
Germans preparing a dictionary, Americans developing fonts and, finally, a Dutchman developing the transliteration scheme for Sanskrit my frustration was mounting! Then I came across the Bharat Operating System Solutions (BOSS). Finally, this was real work being done by our countrymen to support Sanskrit and other Indian languages. BOSS is an Indian GNU/Linux distribution developed by C-DAC and is customised to suit the Indian needs. Figure 3 shows the logo of BOSS.
There are server, desktop and educational versions of BOSS available. The desktop version of BOSS is called Boss Desktop and the educational version is called EduBOSS. The latest release of the BOSS Desktop and EduBOSS is BOSS version 6, named Anoop, which uses the GNOME Desktop Environment 3.14. BOSS Desktop has many provisions for users of Indian languages. Currently, 18 Indian languages are supported by BOSS Desktop including Sanskrit, Hindi, Tamil, Telugu and Malayalam.
In BOSS, inputs can be given in Indian languages also. An input method called Ibus provides onscreen display for input method switching involving character sets of different Indian languages. The Orca screen reader is enabled to read out the text on the screen. But when Indian languages are read by Orca, the accent is slightly anglicised. Let us hope future versions of BOSS will give better performance.
The educational version, EduBOSS, is customised for Indian schools. There are many games available with EduBOSS. These games can be further modified to help children learn Sanskrit. For example, the game called Gbrainy offers a variety of mathematical problems. This game can be modified to include Vedic mathematical problems. Similarly, the KDE based game Kanagram, which offers puzzles based on English anagrams, can be modified to include Sanskrit anagrams. I hope somebody will take up this challenge and modify these games, so that a lot of children can have the best of both worlds – that of Sanskrit and open source software.
Indian Heritage Group of C-DAC
While searching for the details of BOSS, I came across the Indian Heritage Group (IHG) of C-DAC, whose group coordinator is Dr P. Ramanujan. IHG is responsible for Sanskrit and Vedic processing using computers. I dont remember the book in which I read that Srinivasa Ramanujan had single-handedly derived every mathematical equation ever conceived by the western intellects collectively. When I came across the works of Dr P. Ramanujan, I had the same feeling. Whatever the entire western community has done to preserve and propagate Sanskrit has been done single-handedly by Dr P. Ramanujan.
I am not qualified enough to comment on his works. My knowledge of Sanskrit is not adequate to assess his brilliant work. But I feel I am privileged to discuss the work of Dr Ramanujan in the field of Sanskrit related software. He has created a database of over 30,000 sutras from the sastras all by himself, named Sakala Sastra Sutra Kosa. He was also instrumental in the development of ISCII (Indian Script Code for Information Interchange), for which he developed the Vedic part. He developed a software called DESIKA to generate and analyse Sanskrit words. DESIKA software can be used for noun generation, verb generation for all tenses, grammatical analysis of words in a sentence, etc. He was also responsible for digitising a lot of old Sanskrit manuscripts. IHG has also developed other software like C-VYASA, which can be used as a Vedic editor and Sanskrit authoring system. The group has developed a searchable knowledge base of Vedas. Currently, IHG is developing software called Swadhyaya, which is a self-teaching system for Sanskrit.
Both western as well as Indian computer scientists have contributed to the development of computing for Sanskrit. Providing more and more computing tools for Sanskrit processing will definitely attract a large number of young people to Sanskrit. But it is not just the case of Sanskrit benefiting from computer science alone; it could be the other way round also. Paninian grammar of Sanskrit is considered as unambiguous grammar by many linguists and grammarians. In the field of Natural Language Processing (NLP), it is absolutely essential to have unambiguous grammar. Paninian grammar might give a better insight to solving this long standing problem. Similarly, the hidden treasures of Vedic mathematics could also help computer science advance further. So let us hope this mutually beneficial interaction between computer science and Sanskrit will continue and prosper in the future also.















