


























































In todays world, data is knowledge and is increasing each day by leaps and bounds. The data versus time graph shows exponential increase. We cant erase this data, as it is mined to fetch very useful information. For example, Sensex data is stored and read to make predictive analyses about stocks. The claims data of the insurance companies is analysed to detect fraudulent claims. Even the DNA data is being studied to find cures for genetic diseases. Hadoop is the open source technology that handles this huge amount of data. In Hadoop, data is stored in HDFS in the form of data chunks, which are distributed across the nodes of the cluster. But the basic problem of Hadoop is that it is not a database, and does not have the facility to write many times, and that, too, in real-time. Hadoop is used for batch processing, and works on the principle of write once, read many times. HBase has been developed to address this problem.
HBase is a distributed column-oriented database built on top of HDFS. It is the Hadoop application to use when you require real-time read/write random access to very large data sets. The HBase project was started by Chad Walters and Jim Kellerman towards the end of 2006 at the company called Powerset. It was modelled after Googles Big Table. HBase is not relational and does not support SQL, but unlike relational databases it can host very large, sparsely populated tables on clusters made of commodity hardware.
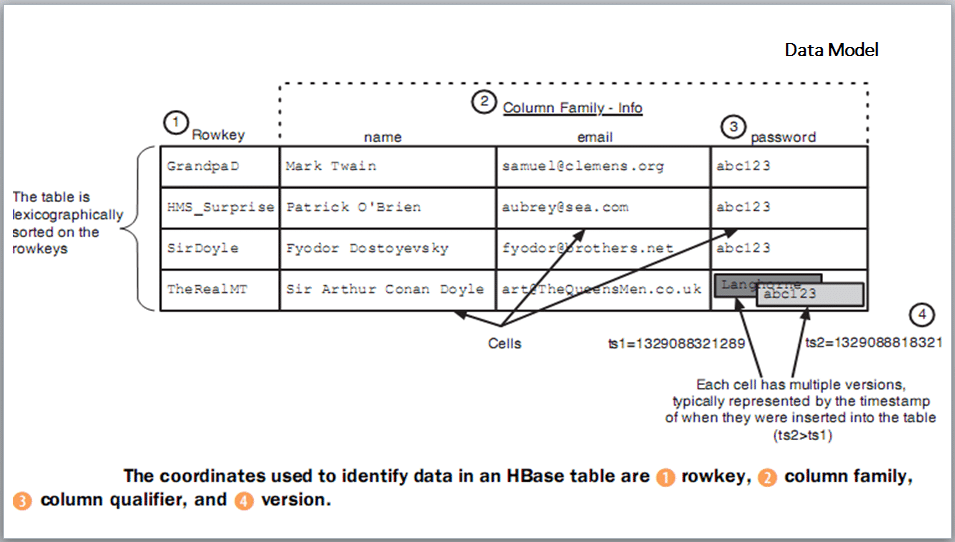
In HBase, applications store data in labelled tables, where tables are made of rows and columns. The intersections of row and column coordinates are versioned, and by default their version is time stamped and auto-assigned by HBase at the time of cell creation. The table row keys are byte arrays, so anything can serve as the row key. Table rows are sorted by row keys, where the sort is byte ordered. Row columns are grouped into column families, which have a common prefix with column family information as name, email and password. A table column family must be specified up front as a part of the table schema definition, but new column family members can be added on demand. Tables are automatically portioned horizontally by HBase into regions. Each region comprises a subset of table rows; the subset consists of elements where the first row is taken into account and the last row is excluded. The last row acts as the first row of the other region. Initially, all the data is stored in one region server, but as the data grows and crosses a configurable size threshold, it splits to two region servers. In the context of locking, the row updates are atomic, no matter how many row columns constitute the row level transaction.
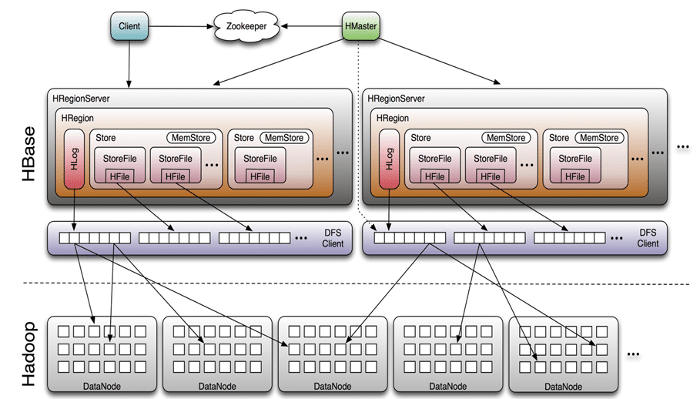
HBase is made up of an HBase master node orchestrating a cluster of one or more region servers as workers. The HBase master is responsible for bootstrapping the first time install, for assigning regions to the registered region servers and for recovering region server failures. HBase depends on Zookeeper and, by default, it manages a Zookeeper instance as the authority of the cluster state, although it can be configured to use an existing Zookeeper cluster instead.

Installation
To install HBase, download the stable release from an Apache Download Mirror (the link is http://www.apache.org/dyn/closer.cgi/hbase/) and unpack it on your local file system, by running the command tar zxvf hbase-0.96.1.1-hadoop2-bin.tar.gz. HBase needs to know where Java is installed, so set JAVA_HOME in the environment variables. Start HBase by running the command ./bin/start-hbase.sh from the HBase directory, and open the HBase shell by running the command ./bin/hbase shell from the HBase directory. In the HBase shell, try the commands given below to create a table.
create mytab, cf1,cf2 put mytab, row1, cf1:a, 1000 put mytab, row2, cf1:a, 2000 put mytab, row3, cf1:a, 3000 put mytab, row3, cf2:a, 4000 scan mytab.
Congrats! You have your first code with HBase. Now lets look at what happened.
Create: Creates a new table identified by mytab and Column Family identified by cf1
Put: Inserts a new record into the table with row identified by row..
Scan: Returns the data stored in the table
Get: Returns the records matching the row identifier provided in the table
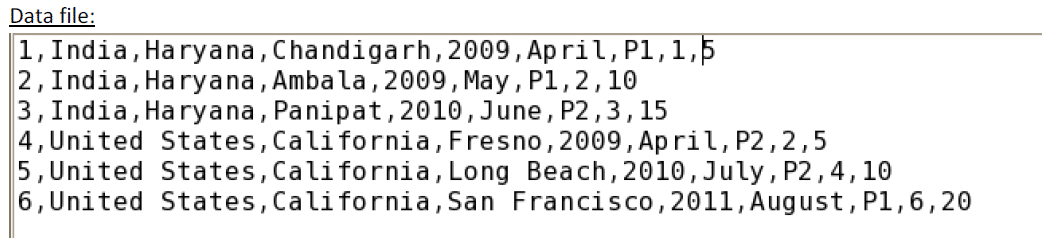
Now let us see how to create and populate the HBase table using Java. This data has to be inputted into a new HBase table to be created through JAVA APIs.
The following column families have to be created: sample,region,time.product,sale,profit.
The column family region has three column qualifiers: country, state, city.
The column family time has two column qualifiers: year, month.
package Hbase;
importjava.io.BufferedReader;
importjava.io.File;
importjava.io.FileReader;
importjava.io.IOException;
importjava.util.StringTokenizer;
importorg.apache.hadoop.conf.Configuration;
importorg.apache.hadoop.hbase.HBaseConfiguration;
importorg.apache.hadoop.hbase.HColumnDescriptor;
importorg.apache.hadoop.hbase.HTableDescriptor;
importorg.apache.hadoop.hbase.client.HBaseAdmin;
importorg.apache.hadoop.hbase.client.HTable;
importorg.apache.hadoop.hbase.client.Put;
importorg.apache.hadoop.hbase.util.Bytes;
public class readFromFile {
public static void main(String[] args) throws IOException{
if(args.length==1)
{
Configuration conf = HBaseConfiguration.create(new Configuration());
HBaseAdminhba = new HBaseAdmin(conf);
if(!hba.tableExists(args[0])){
HTableDescriptorht = new HTableDescriptor(args[0]);
ht.addFamily(new HColumnDescriptor(sample));
ht.addFamily(new HColumnDescriptor(region));
ht.addFamily(new HColumnDescriptor(time));
ht.addFamily(new HColumnDescriptor(product));
ht.addFamily(new HColumnDescriptor(sale));
ht.addFamily(new HColumnDescriptor(profit));
hba.createTable(ht);
System.out.println(New Table Created);
HTable table = new HTable(conf,args[0]);
File f = new File(/home/training/Desktop/data);
BufferedReaderbr = new BufferedReader(new FileReader(f));
String line = br.readLine();inti =1;String rowname=row;
while(line!=null &&line.length()!=0){
System.out.println(Ok till here);
StringTokenizer tokens = new StringTokenizer(line,,);
rowname = row+i;
Put p = new Put(Bytes.toBytes(rowname));
p.add(Bytes.toBytes(sample),Bytes.toBytes(sampleNo.),Bytes.toBytes(Integer.parseInt(tokens.nextToken())));
p.add(Bytes.toBytes(region),Bytes.toBytes(country),Bytes.toBytes(tokens.nextToken()));
p.add(Bytes.toBytes(region),Bytes.toBytes(state),Bytes.toBytes(tokens.nextToken()));
p.add(Bytes.toBytes(region),Bytes.toBytes(city),Bytes.toBytes(tokens.nextToken()));
p.add(Bytes.toBytes(time),Bytes.toBytes(year),Bytes.toBytes(Integer.parseInt(tokens.nextToken())));
p.add(Bytes.toBytes(time),Bytes.toBytes(month),Bytes.toBytes(tokens.nextToken()));
p.add(Bytes.toBytes(product),Bytes.toBytes(productNo.),Bytes.toBytes(tokens.nextToken()));
p.add(Bytes.toBytes(sale),Bytes.toBytes(quantity),Bytes.toBytes(Integer.parseInt(tokens.nextToken())));
p.add(Bytes.toBytes(profit),Bytes.toBytes(earnings),Bytes.toBytes(tokens.nextToken()));
i++;
table.put(p);
line = br.readLine();
}
br.close();
table.close();
}
else
System.out.println(Table Already exists.Please enter another table name);
}
else
System.out.println(Please Enter the table name through command line);
}
}
Before running the above Java code make sure that you have the following JAR files in the build path, as the program is dependent on these files, namely, commons-logging-1.0.4; commons-logging-api-1.0.4; hadoop-core-0.20.2-cdh3u2; hbase-0.90.4-cdh3u2; log4j-1.2.15 and zookeeper-3.3.3-cdh3u0.
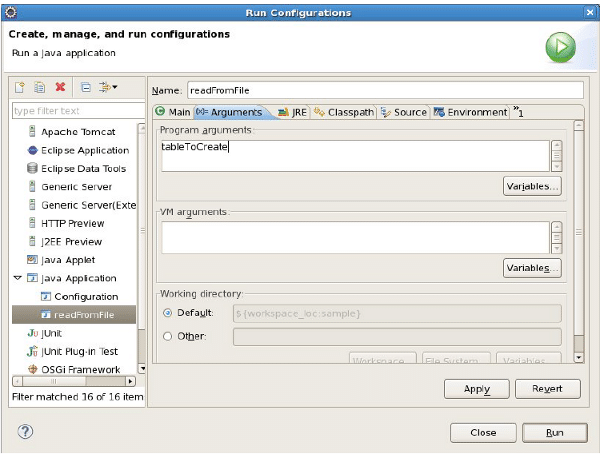
Run the program after providing the table name through the command line, as shown in Figure 5.
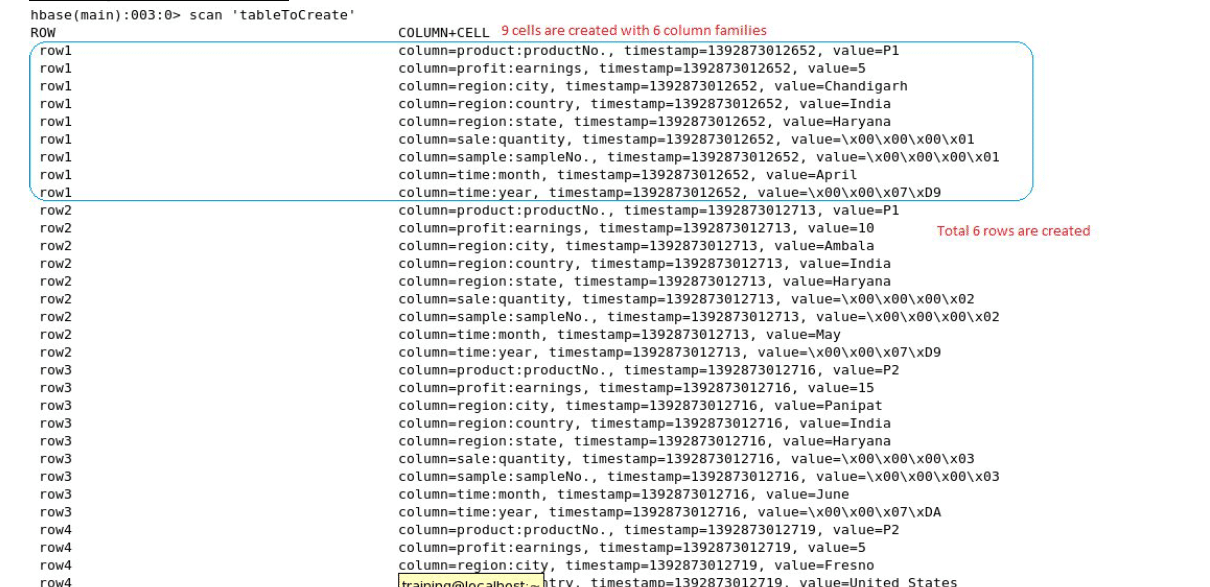
The output of scanning the table is shown in Figure 6.
To conclude, HBase is quite useful for real-time read write operations on big data sets which need to be stored on HDFS.















