


























































Due to the increased competition, organisations need to process their data (in motion) at very short time intervals. With the current focus on volume, variety and velocity of data, newer architectures have come up that seek to emphasise Brewers CAP theorem while relaxing the stringent requirements of a two-phase commit model. As exemplified by the NoSQL (Not only SQL) movement, it is common to see discussions revolve around Elasticsearch, Redis, Riak, MongoDB, among others, at start-up and tech community events.
The other driver is the machine learning, analytics and data science community, and companies that work with sophisticated models in tandem with business. Since the data is very large, most of the compute and storage infrastructure is powered on clusters humming along with Hadoop, Spark, etc, in the cloud.
Thus, there is a spectrum of architectural choices that span from disk-oriented, row-centric, relational models and column-oriented data warehouses for OLAP, to distributed key-value or document stores and new SQL models with high concurrency requirements.
The other set of choices an organisation needs to make relates to the tolerance to data loss, storage failure, inconsistent state issues, lost transactions and poor performance metrics, depending on where the product or the service is in terms of the number of customers. Thus, as the traffic builds up, new challenges and bottlenecks are identified.
Yet another set of choices emanate from the technical debt that your team has accumulated. Thus, a hack using MongoDB by a start-up (either due to lack of design skills or paucity of time) is different from a team that decides to use static typing, interfaces and data structures explicit in its programming model to exploit the powerful capabilities of Redis key-value store. There could be another team with high transactional integrity requirements, which uses a JSON-friendly distributed data store.
Due to the large diversity of data-centric applications and products that are being built from the ground up, decisions and choices have to be made with respect to the database that should be used. This article lists some of those choices while keeping the spotlight on data (data at rest vs data in motion).
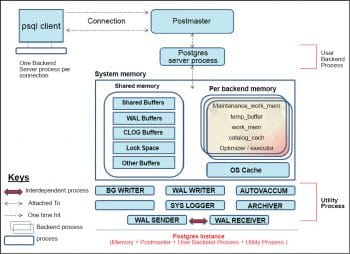
Relational model
The notion of data is one of data at rest as in relational databases like MySQL, PostgreSQL etc.
The various components, transaction logs are highlighted in the Figure 1. There is the familiar SQL interface for the database OLTP and OLAP capabilities are consumed through a combination of drivers, modules, SQL extensions, application programming interfaces and language bindings.
Data in motion
How data is received, how it is processed and then consumed within the context of its spatial temporal attributes, is beginning to determine the choice of databases.
There is also a subtle shift in terminology from databases to the notion of a data store.
A data store allows distribution of data across servers. This has two benefits: (a) scalability, and (b) improved performance for both updates and queries.
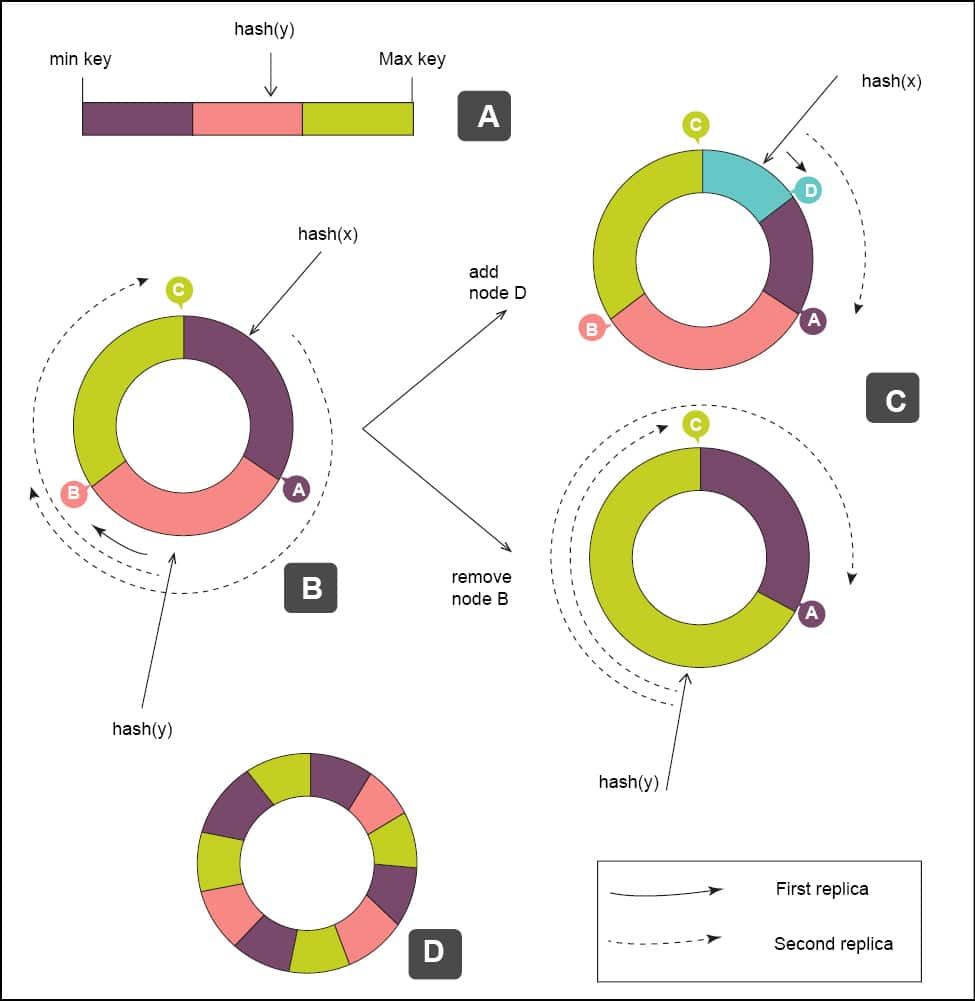
Consistent hashing is a promising technique, which is used to implement data distribution and introduces the notion of a key element. In the context of a relational database, this is the primary key and, in a data store, this is just the key.
The most important characteristic is that there can only be a single entry for the key in a data store. This single entry is assigned to a numerical value, which is assigned to a specific server. Thus, the specific key is always assigned to the same server for storage and querying.
The advantage is that the load can be distributed across the servers at the cost of reliability. If any of the servers crash, the data stored on that server becomes unavailable. With an increasing number of servers, the probability of a crash keeps going up.
To improve reliability, we apply the consistent hashing technique.
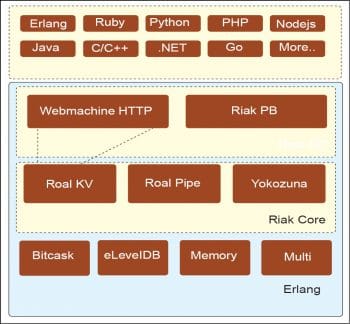
The data stores that implement this approach are:
- Amazon Dynamo
- Memcached
- Project Voldemort
- Apache Cassandra
- Skylable
- Akkas hashing router
- Riak, a distributed key value database
RDF (Resource Description Framework)
The RDF data model is based on the idea of making statements about resources in the form of subject-predicate-object expressions (triples).
Subject is the resource. Predicate refers to the traits of the resource and expresses a relationship between the subject and the object.
RDF is an abstract model with several serialisation formats like Turtle, JSON-LD and RDF/XML.
For an example, look at the following sample RSS 1.0 blog feed:
<?xml version=1.0?> <rdf:RDF xmlns:rdf=http://www.w3.org/1999/02/22-rdf-syntax-ns# xmlns=http://purl.org/rss/1.0/> <channel rdf:about=http://www.xml.com/xml/news.rss> <title>XML.com</title> <link>http://xml.com/pub</link> <description> XML.com features a rich mix of information and services for the XML community. </description> <image rdf:resource=http://xml.com/universal/images/xml_tiny.gif /> <items> <rdf:Seq> <rdf:li resource=http://xml.com/pub/2000/08/09/xslt/xslt.html /> <rdf:li resource=http://xml.com/pub/2000/08/09/rdfdb/index.html /> </rdf:Seq> </items> </channel> <image rdf:about=http://xml.com/universal/images/xml_tiny.gif> <title>XML.com</title> <link>http://www.xml.com</link> <url>http://xml.com/universal/images/xml_tiny.gif</url> </image> <item rdf:about=http://xml.com/pub/2000/08/09/xslt/xslt.html> <title>Processing Inclusions with XSLT</title> <link>http://xml.com/pub/2000/08/09/xslt/xslt.html</link> <description> Processing document inclusions with general XML tools can be problematic. This article proposes a way of preserving inclusion information through SAX-based processing. </description> </item> </rdf:RDF>
Since the collection of RDF statements intrinsically represents a labelled directed graph, as a data model, it is more naturally suited to certain kinds of knowledge representation other than the relational model. When the data model imbues semantic Web applications, then RDF shines like in RSS, FOAF, conceptual graphs and topic maps. XUL uses RDF extensively for data binding.
It is remarkable that RDF database systems are the only standardised NoSQL solutions built on a simple, uniform data model and a powerful declarative query language for RDF graphs called SPARQL. Taking a resource-centric approach maps the RDF data model to object oriented systems and RESTful architectures.
NoSQL
Also referred to as Not only SQL, this is an umbrella term to describe a model of non-relational database systems. NoSQL data stores tend to be inherently distributed, schema-less and horizontally scalable.
A broad classification encompasses:
- Key value data stores: The predominant data structure is a persistent hash table. Examples are BerkeleyDB, MemcacheDB, Tokyo Cabinet, Redis and SimpleDB.
- Document data stores: These are key value stores, wherein the values are interpreted as semi-structured data and not a blob. Examples are CouchDB, MongoDB and Riak.
- Graph data stores: These have a directed labelled graph model as the main data structure. Examples are neo4j, InfoGrid, HypergraphDB, AllegroGraph, 4store and Virtuoso.
- Wide column data stores: Also known as an extensible record set, these have a column as the basic unit. A column is created for each row, and consists of a key and value pair. Usually the third entry is a time stamp. Examples are Apache Cassandra, HBase and SimpleDB.
Semi-structured data
Semi-structured data is a form of structured data where the data is annotated by tags, markers or headers to distinguish elements and enforce hierarchies of records and fields within the data.
Some important indicative examples are given below.
Email headers:
From: Fred Wilson <Fred@usv.com> Reply-To: Fred Wilson <Fred@usv.com> Sender: FeedBlitz <feedblitz@mail.feedblitz.com> Return-Path: 39646264_304_4941999_fbz@mail.feedblitz.com To: Saifi <saifi@containerlogic.co> Date: Thu, 07 May 2015 07:14:54 -0400 MIME-Version: 1.0 Content-Type: multipart/alternative; charset=UTF-8; boundary=f33dBL1tz_mIME_pART_bOUNDARY==39646264==v1_ Message-ID: <MAIL04sPYxXMBJtZ2Ib007e3aa8@Mail04.feedblitz.com> X-OriginalArrivalTime: 07 May 2015 11:14:54.0345 (UTC) FILETIME=[0B48AF90:01D088B7]
X.509 certificate fragment:
<element name=X509Data type=ds:X509DataType/> <complexType name=X509DataType> <sequence maxOccurs=unbounded> <choice> <element name=X509IssuerSerial type=ds:X509IssuerSerialType/> <element name=X509SKI type=base64Binary/> <element name=X509SubjectName type=string/> <element name=X509Certificate type=base64Binary/> <element name=X509CRL type=base64Binary/> <any namespace=##other processContents=lax/> </choice> </sequence> </complexType> <complexType name=X509IssuerSerialType> <sequence> <element name=X509IssuerName type=string/> <element name=X509SerialNumber type=integer/> </sequence> </complexType>
JSON dump of Docker container:
[{
Architecture: amd64,
Author: Saifi Khan saifi@containerlogic.co,
Comment: ,
Config: {
..
Entrypoint: [
startdb.sh
],
Env: [
PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin
],
Hostname: 5bf0de3d0926,
Image: d9065eab448785cb11377 f381135f1e345d31883ae39bb646e9129ea9b3b05b3,
Memory: 0,
MemorySwap: 0,
NetworkDisabled: false,
..
Volumes: null,
WorkingDir:
},
Container: 10dee820e7e5dced36523ed7ab 7f09aaf8d177b657985514c120f7a1605e96b7,
ContainerConfig: {
..
},
Hostname: 5bf0de3d0926,
Image: d9065eab448785cb11377f3811 35f1e345d31883ae39bb646e9129ea9b3b05b3,
..
},
Created: 2015-05-05T17:55:02.969770577Z,
DockerVersion: 1.3.2-dev,
Id: 2d37849cf381b7023f067b4 dd4445d21981e43d9fced1ed345ff614d1170a65e,
Os: linux,
Parent: d9065eab448785cb11377f 381135f1e345d31883ae39bb 646e9129ea9b3b05b3,
Size: 0,
VirtualSize: 17513894
}]
As seen in the examples above, header fields, JSON or XML entities belonging to the same class type may have different attributes even though they are grouped together.
Two important points here are:
- Semi-structured data usually has a self-describing structure
- The ordering constraint is not important
This is in contrast to the formal relational structure that is enforced by RDBMS and data tables.
With the preponderance of JavaScript in Web-centric applications and services, attribute key pairs are expressed using JSON and consumed using REST endpoints.
Thus key-value data stores can use the JSON format to natively store data. CouchBase and MongoDB take this approach.
Schema-less databases
The rallying cry of the MongoDB evangelist is that it is a schema-less database. This needs to be understood in the context of the database and the in-memory data structure. First of all, there is still an implicit inferred schema. The database also supports non-uniform data types, for example, relational schema for the student table.
create table student( rollno BIGINT, name VARCHAR(255), school CHAR(64))
Now, if you create an entry:
insert into student values( khushi, 2628, manu high)
The query will generate an error since the type(s) of the data does not match the schema.
Since the student type is a record, a schema-less database would support non-uniform types, i.e., each of the following can be stored:
{name : khushi}
{name : khushi, rollno : 2628}
{name : khushi, rollno : 2628, school : manu high}
This is the flexibility of a NoSQL data store; however, there are three points to note here.
1. The information about the type and structure of the data shifts to the code that you write.
2. The implicit schema (a data type) is a data structure in your code. Depending on the language, it would be represented as a struct, class, a hash, a dictionary, an associative array or a map that is also the representation of the schema-less data structure in memory.
3. As a programmer, you are going to encounter errors for any data that does not match the data type.
A useful approach is to model a set of accessory methods and related logic, which provide a facade to the schema-less data structure. This one level of indirection decouples other parts of your code from the core structure.
How an RDBMS goes schema-less
Building on the discussion above, we can see that a non-uniform type is characterised by an indeterminate number of key-value pairs.
As a result:
1. A key may refer to a JSON object or an array of multiple key-value pairs.
2. A key may have additional custom data.
All the above can be modelled with additional tables in an RDBMS using custom columns in a table, a TEXT field to embed semi-structured data like JSON, and an attribute table that joins the custom data.
This is a pragmatic approach to support ad hoc schema-less data over a relational schema.
A schema as a contract
So from the point of view of a service, what exactly is a schema?
XML vocabulary has DTD, JSON layout maps for the schema, and an RDMBS has its schema defined in terms of integrity constraints. In more generic terms, the notion of database schema plays the same role as the notion of theory in predicate calculus.
A schema, in some sense, is a documented form of the contract that a particular component implements. In other words, as an architect would say, a schema is an interface!
NoSQL PostgreSQL
Let us look at an example of extensible schema in the context of PostgreSQL, an ORDBMS (Object Relational Database Management System). Traditionally, PostgreSQL has been well known for rich SQL and transactional interfaces and capabilities.
With the release of version 9.4, PostgreSQL has stepped into the world of Not only SQL by bringing in two new featuresHStore and JSONB.
JSONB is a binary version of the JSON format, which supports indexing and a rich set of JSON operators that include containment and existence. JSONB supports btree and hash indexes. GIN or generalised inverted indexes can be used to efficiently search for keys or key-value pairs occurring within a large number of JSONB documents.
Let us look at the example of the Docker inspection JSON fragment we discussed in the section on semi-structured data, and see how we can use the JSON operators of PostgreSQL.
Lets assume that dockerimages refers to the images and dockerinst refers to the JSON fragment for an image.
SELECT dockerinst->Config, dockerinst->Container
FROM dockerimages
WHERE dockerinst @> {Image : d9065eab448785cb11377f3 81135f1e345d31883ae39bb646e9129ea9b3b05b3}
We have accessed specific fields or array chunks in a JSON fragment using the familiar SQL interface. Next, we explore the approach PostgreSQL adopts to support key-value pairs within a single PostgreSQL value.
The hstore module implements the hstore data type for storing sets of key-value pairs. In other words, hstore is a key-value store within PostgreSQL.
Since keys and values are simple text strings, this will be useful for working with semi-structured data and rows that have multiple attributes. Here is an example that highlights how to use the feature.
To install the hstore module, you need to run this query in the database you wish to use hstore on:
CREATE EXTENSION hstore;
Create the table with the hstore type to store the features of a smartphone:
CREATE TABLE smartphones ( id serial PRIMARY KEY, name VARCHAR(255), features hstore);
Set the contents of the hstore as key-value pairs:
INSERT INTO smartphones (name, features) VALUES ( Asus Zenfone 6, os => Android v4.3 (Jelly Bean) chipset => Intel Atom Z2580, cpu => Dual-core 2 GHz, gpu => PowerVR SGX544MP2 );
An SQL query to retrieve data from an hstore:
SELECT name, features->os AS os FROM smartphones WHERE features @> cpu => Dual-core 2 GHz ::hstore
With the current 9.4/9/5 PostgreSQL release, GIN and GIST indexes now support hstore columns with excellent performance metrics.
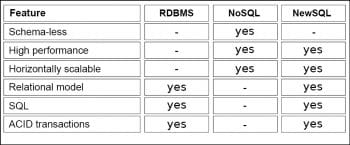
NewSQL
With the Infrastructure as a Service (IaaS) model, the biggest shift in architecture design is that consistency, transactions and storage optimisation are all sought in the cloud as we seek scalability at all levels.
NewSQL is an emergent class of database systems that have a combination of RDBMS and NoSQL capabilities. NewSQL seeks to provide the scalability of NoSQL data stores for online transaction processing (OLTP) read-write workloads, while maintaining the ACID (atomicity, consistency, isolation and durability) property of RDBMS. Examples are NuoDB (a distributed cloud based database), VoltDB (high performance through in-memory operations), ScaleDB and GenieDB (both plug into MySQL), and Clustrix, which can work with any SQL database.
Figure 6 lays out the comparison between the various approaches.
Re-CAP Brewers theorem
According to the CAP theorem, any networked, shared-data system can have at most two of three desirable properties, that is, (C)onsistency, (A)vailability and (P)artition.
Without having a clear understanding of what the CAP theorem states or rather what it restricts, most geek discussions project it as a 2 of 3 formulation. This is not helpful! The CAP theorem helps explore design space, when we seek an answer to the following questions: What capabilities do we seek in a system during a network partition? and ”What expectation can we have about the state of the system during partition recovery”.
As Brewer himself observes:
- The state on both sides must become consistent
- There must be compensation for the mistakes made during the partition mode
Version vectors and commutative replicated data types (CRDT) are some of the newer approaches to manage invariants during partitions.
Thus, the choice of a data-store will depend heavily on the services invariants and operations.
References
[1] Karger, David et al (1997) Consistent hashing and random trees: distributed caching protocols for relieving hot spots on the World Wide Web http://dl.acm.org/citation.cfm?id=258660
[2] Basho documentation: https://basho.com/tag/consistent-hashing/
[3] Aslett, Matthew (2011) How Will The Database Incumbents Respond To NoSQL And NewSQL : http://cs.brown.edu/courses/cs227/archives/2012/papers/newsql/aslett-newsql.pdf
[4] Stonebraker, Micheal (2011) New SQL: An Alternative to NoSQL and Old SQL for New OLTP Apps: http://cacm.acm.org/blogs/blog-cacm/109710-new-sql-an-alternative-to-nosql-and-old-sql-for-new-oltp-apps/fulltext
[5] Catell, Rick (2010) Scalable SQL and NoSQL data stores: http://dl.acm.org/citation.cfm?doid=1978915.1978919
[6] Arto Bendiken (2010) How RDF Databases Differ from Other NoSQL Solutions: http://blog.datagraph.org/2010/04/rdf-nosql-diff
[7] Stonebraker, Michael (2005) C-store: A column oriented database: http://db.lcs.mit.edu/projects/cstore/vldb.pdf:
[8] Wide column store: http://nosqlguide.com/column-store/nosql-databases-explained-wide-column-stores/
[9] PostgreSQL JSONB: http://www.postgresql.org/docs/9.4/static/datatype-json.html
[10] PostgreSQL hstore module: http://www.postgresql.org/docs/9.4/static/hstore.html
[11] Chang, Dean et al (2006) Bigtable: A Distributed Storage System for Structured Data: http://research.google.com/archive/bigtable.html
[12] Golab, Wojciech et al. Eventually Consistent: Now what you were expecting: http://queue.acm.org/detail.cfm?id=2582994
[13] Dahlin et al (2011) Consistency, Availability and Convergence UTCS TR-11-22, University of Texas at Austin.















